Recently I had the chance to work with one of the world’s largest insurers on improving their business processes. In discussing insurance workflows and data, we all recognized that every twenty-first century dataset contains location. What our sessions highlighted was the fact that every business process in insurance requires location data. The more we explored business units, governance, data management systems and the way people work, the more we hit on the notion of the location domain. Let me explain.
Domain describes a discrete set of land or computers that share a common purpose, owner or role. It’s also a sphere of knowledge, influence, or activity. The location domain is the influence of location within these business activities and systems, how it enables new or improved knowledge and can drive significant process improvement.
Fooled into Complacency
Think about risks and insured people and assets. Risks are often indistinct; they influence a large area without an exact or precise boundary. The insured are more discrete—they contain an address, a building, property, or asset which can be identified to a known location somewhere in the world. This has led many of us into a false sense of security about the accuracy of location specific data.
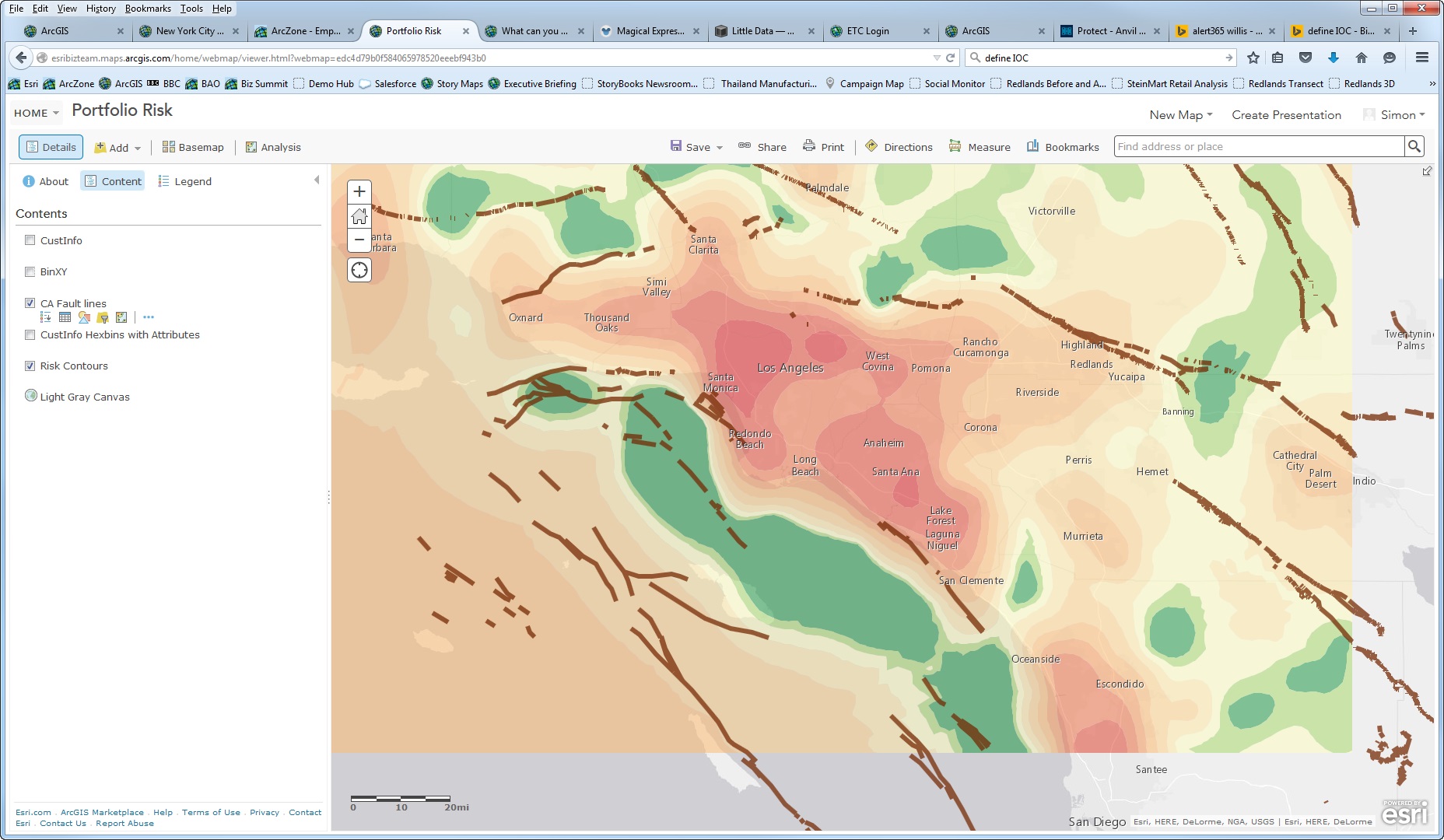
When we look at insurance, many times the people within these boundaries are treated the same—as if all risks are equal but change dramatically at the edge. Some US ZIP codes are huge. Tonopah, Nevada is a little larger than the state of Maryland. It encompasses 10,000 square miles and is the largest ZIP code in the lower 48 conterminous United States. Obviously, the risk located in this ZIP code will not be the same over all these miles.
The shape of a ZIP code also impacts analysis and location accuracy. The center, or centroid, is often not in the middle of the actual shape. We need detailed understanding of a shape’s topology to make sure a point is placed correctly in the center within the shape itself.
Take a look at the diagram below. This diagram shows real parcel outlines from a small street near my house. Look at how geocoding techniques and parcel geometry give different answers for the same set of inputs.

Does all this matter? Yes, a lot. Too often we assume that location is just another attribute in our spreadsheets and databases. Many times, after the location data is created it’s never updated. Revisions and edits aren’t edited or tracked. As a result, we lose understanding of what’s changed and why. You’d never do that with your policy pricing—so why let it happen to the geography of that policy?
I’ve seen lat-longs in policy dataset that were created 25 years ago. They were built with geocoding software which interpolated evenly along a road or used maps that are now more than 50 years old.
Today’s data is orders of magnitude better. We have near global coverage at street level. In every developed country you can find a house, business, or address easily. There’s a marker placed on its true location that was either measured by a vehicle, surveyed on the ground, taken from hi-resolution satellites, or hand-positioned by a human expert from up-to-date, authoritative maps. No more interpolation—an inexact science at best and damaging to a company’s reputation and bottom line at worse.
So have companies gone back and updated their data as geocoding and address management have changed? In most cases no. If there’s a lat-long it survived pretty much untouched since the data was first created. Just about every other descriptive information might have changed in them but the location doesn’t because it is in our minds, a static location on the earth.
This isn’t acceptable anymore. The way we create and manage location references has changed so much that the lat-long we got from old geocoding systems may turn out to be somewhere else entirely.
Are You False-Confident in Your Geo-Data?
Look, people have a false confidence in location data. There’s no escaping this fact. So when there’s been a merger or acquisitions, or new business processes have been written to move policies around, the geographic data and accuracy usually is not reassessed.
If your data is bad you’re going to end up with bad business.
Good data governance is important. Insurance organizations have been leaders in developing ‘systems of record’. But geospatial data has been the dirty little secret—often ignored and unwashed. When we build pricing and loss models we agonize over model accuracy and fit. But we often ignore the error at source—geographic uncertainty.
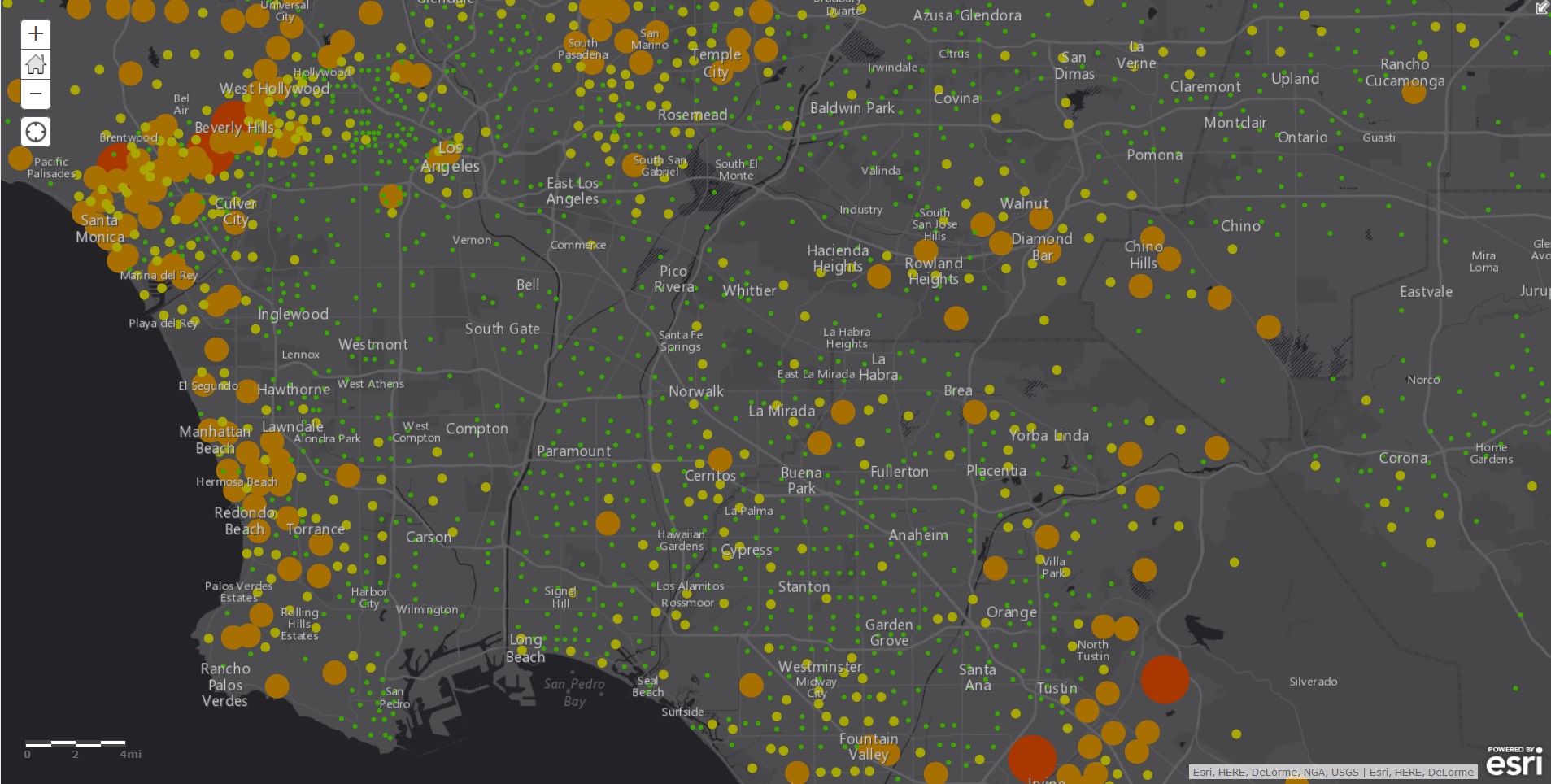
Authoritative location domains link enterprise workflows and systems together. When you have a location strategy you can easily provide changes. You make sure changes propagate across all your systems and the processes that use them. This means your data keeps getting progressively better and your ability to rely on information improves.
Where does this leave you? It means you move from fearing uncertainty to embracing accuracy. Accuracy that flows through all your systems—actuarial, underwriting, claims, and agency—at the point of execution or in new strategies. And all this comes about because you had the foresight and confidence to realize you needed to dust off your geo-fields and datasets. Now wouldn’t that be a refreshing change?
insider
