If you were to pick a phrase or word that is the standout that describes the times we live in, it would be AI. What does AI mean? Typically, popular culture revolves around science fiction ideas such as the movie “The Terminator” or something like that. Although that makes for remarkable story telling, it can be simplified down into programmatic knowledge, or an evolved process designed to save time. This kind of training process allows users to leverage trained networks to then infer data which can be used to identify objects such as trees, pools or rooftops but can also use this kind of knowledge to complete 3d models.
The biggest factor for any data scientist working with this kind of data is how to get the resources needed to perform these tasks and complete the training models in an efficient amount of time. Training experiments can be made to run 24/7, however it is also possible to leverage Virtualization technology and provide VDI (Virtual Desktop Infrastructure) by day and compute by night. This allows users to have VMs (virtual machines) running ArcGIS Pro by day, and then have those VMs shutdown at night. Doing this allows for large scale VMs to then takeover the On Premises Virtual Infrastructure with large scale compute VMs and run Compute or training experiments by night or after normal working hours.
NVIDIA AI Enterprise offers a flexibility to deploy VMs designed to support Deep Learning processes. To setup NVIDIA AI Enterprise similar technical knowledge to deploy 3D capable VMs is a requirement. For the most part, the deployment method used for GPU backed VMs supporting ArcGIS Pro is nearly identical. With this deployment method we leveraged a Dell PowerEdge r750 server to host NVIDIA H100 GPUs. These GPUs are designed strictly with compute in mind and require a specific NVIDIA AI Enterprise license to deploy. This proof of concept leverages an approach running multiple VMs but also leveraging the full power of the host to deliver a larger Virtual Machine utilizing the full capability of the host server.
For information on how to configure NVIDIA AIE Enterprise see the following:
NVIDIA AI Enterprise Deployment Guide
To run this experiment, we leveraged a Dell PowerEdge R750 2U server, configured with VMWare ESXi 7.0.3. The specifications for this system will be provided below. The On-Prem hardware was configured with VDI, and 3D virtualization needs and could benefit from some changes (CPU, Faster storage and more of it, additional RAM) based on this type of Data Science work being performed on a continued basis. This host has the following hardware, and with the exception to the H100 GPUs this server is the same Dell ArcGIS Pro Virtualization Appliance that has been in service the last two years.
- Two Intel Xeon Gold 6354 Processors
- Two NVIDIA Hopper H100 GPUs
- 1024 GB RAM
- Six 960 GB Solid State Hard Drives in a RAID 5 Array
Deep Learning: Looking for optimal configuration
Developing a practical solution based on a neural network model has its distinct phases where training a model is only part of the work. The process begins with the data; what data is available and what spatial and statistical properties it has. Once the data sources are identified and the initial raw dataset is collected, it’s time to decide on the neural network architecture and the way the raw data is converted into the training examples.
Deciding on the neural network architecture, its configuration (hyperparameter values), and the training sample format is an iterative process. This is often task specific and has no universal answer. The quality of the resulting trained model might vary dramatically depending on the chosen combination of the neural network architecture, loss function, curated training samples and their feature normalization, learning rate schedule and the optimizer, etc.
The search for a sweet spot amongst the multitude of permutations of these aspects is an optimization process by itself with data scientists and data engineers in the loop. Through a focused tree of multiple experiments, the developers come to an optimal setup which, with an acceptable likelihood, is going to yield interesting and practical results.
Once an optimal combination of hyperparameter values is understood and suitable training data is identified, the large-scale training of a production-grade model can commence.
Benefits of GPU compute virtualization
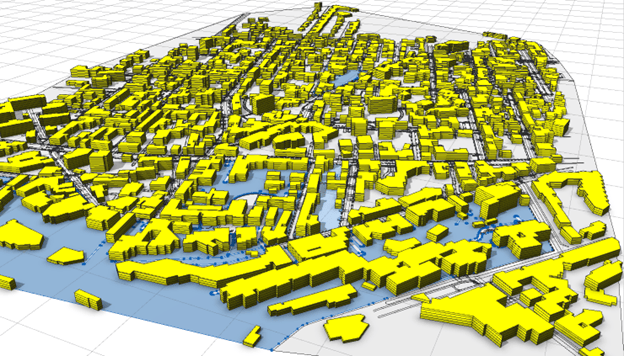
For this blog we used the Urban Scene Generator (USG), an internal R&D project, as a case-study. At the heart of the USG is a generative neural network which, once trained, produces realistic looking and practical distributions of buildings in a user-defined urban area.
The raw datasets, used for building training data, contain large volumes of raster and vector geographic features coming from multiple “prototypical” cities – the cities which were hand-picked for exhibiting high-quality living standards, well-developed infrastructure, and pedestrian accessibility as per Carlos Moreno’s “15-minute city” concept.
For the USG model, the number of input feature rasters is 20+, with some of the features, like Building Coverage Area (BCR) and Floor Area Ratio (FAR) having trivial normalization formulas, while the others, like the Digital Terrain Model raster (a float16 raster representing per-pixel height above sea level), representing a normalization conundrum: the local mean and standard deviation vary dramatically across the different cities and training sample tiles.
Another engineering challenge was maximization of GPU utilization – both compute and vRAM: with the training dataset exceeding 1.5TB, it was a delicate balance between SSD drives I/O, CPU, RAM, and GPU utilization. For example, how much data to cache in RAM; ratio between the online and offline data augmentation; whether the storage format needs to be raw or compressed, etc.
Thus, the classical hyperparameter search for the USG project was not limited to traditional graph configuration and learning rate grid-search. Rather this involved multiple short- to medium-lived experiments on various versions of training data assemblies, its normalization, and data loader implementations.
This is where the versatility of the AI Enterprise running on a Dell PowerEdge R750 with 2 x H100 GPU cards came to play an important role.
With the help of NVIDIA AI Enterprise, we started by splitting the large compute node into four smaller virtual machines with a half-H100 GPU each, equally dividing RAM, and the drive space. These smaller VMs allowed us to run up to four independent training experiments with various versions of the training data and the data loader implementations simultaneously.
After the major performance and normalization questions were answered, we consolidated the four virtual machines into two bigger ones, keeping the two-out-of-four chosen disk states, and allocating one H100 GPU per bigger VM.
At this point, a more fine-grained hyperparameter search, data loader optimizations, and gradient normalization experiments took place. This was similar to the prior 4 VM test, instead, running two versions of the implementation in parallel.
Finally, once we were confident in both the implementation, the schema and normalization of the training samples, chosen hyperparameter values, etc., we continued the experiments with the full node capacity which, thanks to NVIDIA AI Enterprise, took under an hour to set up by merging the two smaller VMs into the final large one with all the CPUs, RAM, SSD drive space, and 2xH100 GPUs. This is where the final “production” quality training was conducted for a few weeks uninterrupted.
It’s worthwhile to note the accelerated performance of the Hopper architecture H100 GPUs. Initially, the USG training experiments were conducted on a comparably equipped system with (8)V100 GPUs. We observed that the (2)H100 GPUs system with NVIDIA AI Enterprise was roughly equivalent or exceeding in compute throughput with a single node, making a local node with NVIDIA AI Enterprise equipped Hopper GPUs a cost-efficient, and flexible on-premises alternative.



Article Discussion: