Spring 2008
Spring 2008 |
||||||||
|
|
||||||||
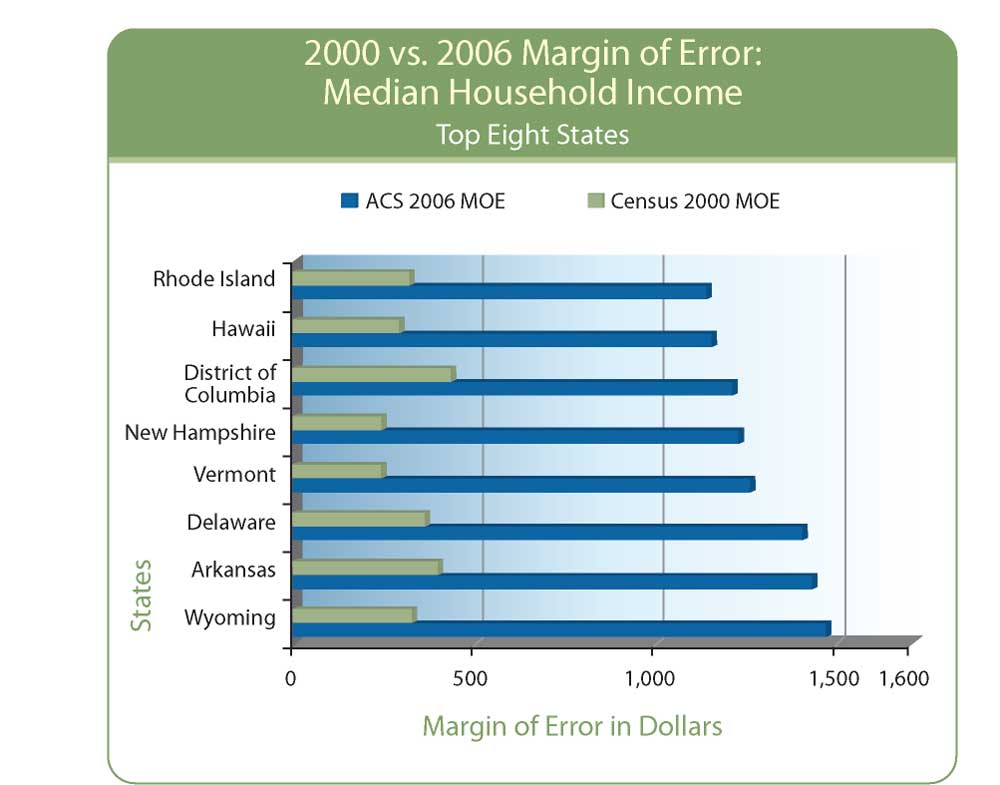
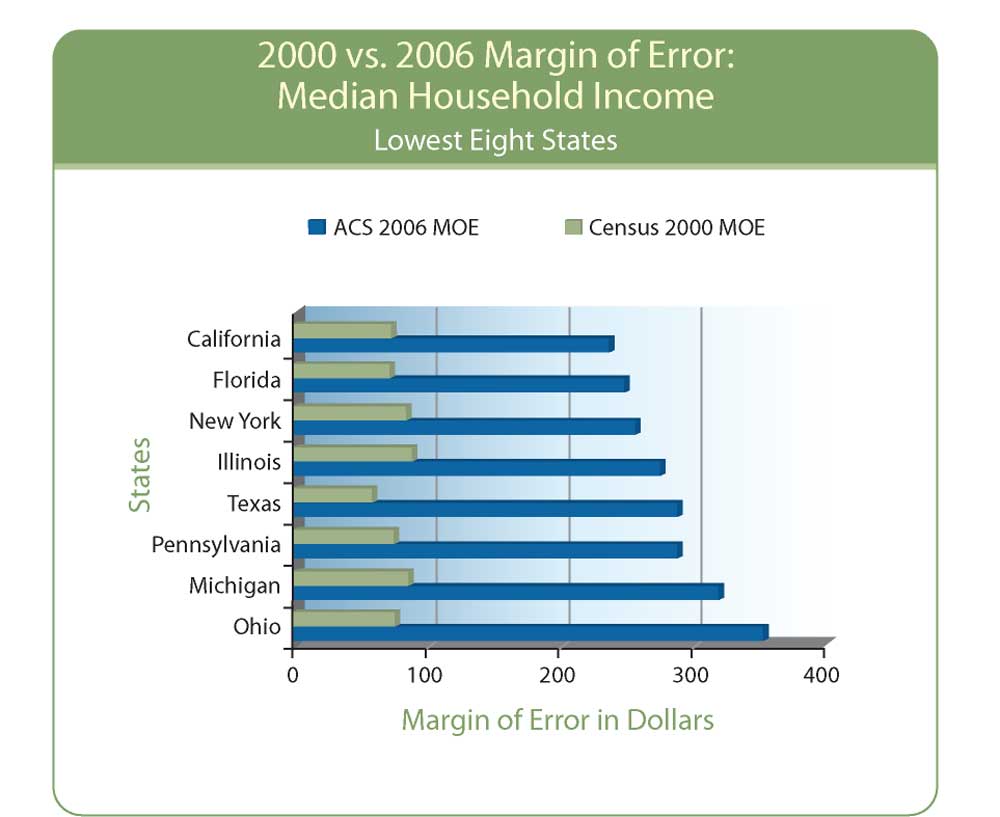
Chart 2 shows the difference in eight states with the smallest MOE for median household income in 2006. Among these states, MOEs in 2006 are certainly smaller than MOEs among the top eight states displayed in Chart 1, but the disparity between Census 2000 and ACS 2006 remains conspicuous, even at the state level. What happens at the tract or block group level? As a general rule, MOE doubles if the size of the base is reduced fourfold. Do the math, and the difference in MOE between an average county population of 98,000 and the average tract population of 4,700 is a factor of 20. MOE increases by a factor of 4.5.
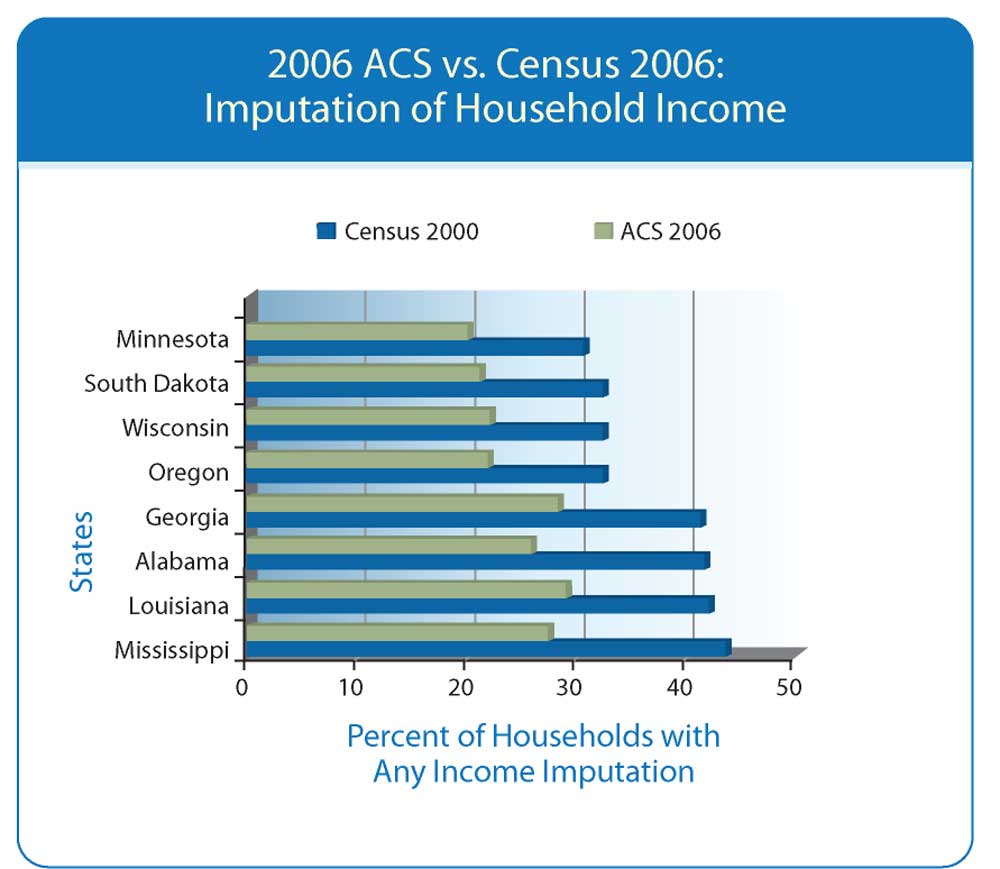
MOE MattersWhat does this mean to the data user? First, it indicates the variability of estimates derived from the ACS. In the example of Nassau County, Florida, median household income in 2006 is $55,925 plus or minus $8,685 at a 90 percent confidence level. Translation: the data user can conclude with 90 percent confidence that the true median household income of Nassau County is somewhere between $47,240 and $64,610, which are the values that bracket $55,925 by a MOE of $8,685. However, confidence intervals of 95 or 99 percent are more common in statistical tests of significance. If the data user prefers a level of confidence higher than 90 percent, MOE would be even larger (more than $10,000 at 95 percent). Second, the variability of estimated change must also be measured. Despite the differences between ACS and the Census 2000 sample, comparisons are inevitable when the small area data from ACS is finally released. (The first five-year averages for all areas are scheduled for release in December 2010.) To compare the estimates, MOE for both surveys must be calculated to estimate MOE of the difference between two estimates. For example, an increase of $5,000 in median household income may be a function of sampling error— not real growth—if MOE is larger than $5,000. One thing is certain now: it will be necessary to incorporate the estimates of sampling error in order to use data from the ACS. Without the standard error estimates, or MOE that are included with all ACS tabulations, it will be impossible to distinguish change from sampling error. MOE matters. Other Sources of ErrorSampling is not the only source of error in ACS data. There are also nonsampling errors to consider. Nonsampling errors can occur in the collection or processing of the data. For example, under- or overcoverage of a population can introduce nonsampling error. Incomplete responses to the survey can introduce nonsampling error. If the errors are random, then the result is increased variability in the sample estimates. However, if the nonsampling error is consistent or systematic, then bias is introduced to the sample estimates. Nonresponse or incomplete responses to a survey are typical sources of nonsampling error, which can be addressed by data collection and tabulation methods. The Census Bureau believes that the larger sampling error that is inevitable with the ACS may be offset by improvements in data collection and reductions in nonsampling error. The extent of imputation for missing household income data by state is lower in the 2006 ACS data than in the Census 2000 sample data. [Imputation is the use of information from another person or household to supply a missing value.] Chart 3 compares the percent of households with some imputation of total household income for states with the largest (Georgia, Alabama, Louisiana, Mississippi) and smallest (Minnesota, South Dakota, Wisconsin, Oregon) rates of imputation in 2000.
Comparing ErrorWhether reducing one aspect of nonsampling error is sufficient to offset the significant increase in sampling error is debatable. Nonresponses or incomplete responses are just one type of nonsampling error. Assuming that sampling error and nonsampling error are independent, total error is a function of both. How much is gained by reducing nonsampling error while increasing sampling error with small samples? Accuracy of Data (2006), a paper from the United States Census Bureau, provides more information on this topic. The final step in the operation converts the sample data collected to estimates of population and housing by weighting the sample data. Census long form data is weighted to reflect the probability of sample selection, then adjusted by ratio estimation to be consistent with complete count tabulations of the population and occupied housing units by various characteristics. The product of the ratio estimation is a reduction in sampling error and possibly bias that could have resulted by simply applying the inverse of the sampling rate. Another advantage of this procedure is that sample estimates are generally consistent with complete counts. The ACS data does not have the advantage of weighting by the complete census counts. Continuous measurement of the population requires more current data to weight the counts. The Census Bureau is using independent population and housing unit estimates to weight the ACS data. Without the census counts to weight the data, the ACS estimates are subject not only to sampling and nonsampling error but also to estimate error. Postcensal estimates are based on the most recent census counts and are subject to their own sources of error from the input data used to the assumptions inherent in each method. All data sources include some error. Sampling and nonsampling error were part of the Census 2000 sample survey too. However, when the error must be reported with the estimate, it's time to pay attention. The ACS sample estimates are more variable than Census 2000 sample estimates. The only way to improve this effect is to increase the sampling rate. Questions from readers are welcome. Please address your questions to lwombold@esri.com. About the AuthorLynn Wombold, chief demographer at Esri, manages data development for Esri including the processing of census data and the development of unique databases such as the demographic forecasts, consumer spending, Retail MarketPlace, and Community Tapestry market segmentation system as well as the acquisition and integration of third-party data. She is also responsible for custom analysis and modeling projects. With more than 31 years of experience, her areas of expertise include population estimates and projections, state and local demography, census data, survey research, and consumer data. Prior to joining Esri, she worked for CACI Marketing Systems and was the senior demographer at the University of New Mexico. Wombold holds degrees in sociology, with a specialty in demographic studies, from Bowling Green State University in Ohio. She has received CACI's Eagle Award for Technical Excellence and Encore Achievers. The author of numerous articles for industry publications, she frequently presents papers on demography. References |