In recent years, the surge in sensor data from drones, satellites, and aerial platforms has made automated feature extraction increasingly important. Artificial intelligence is now playing a key role in turning this raw geospatial data into actionable information, enabling faster processing and deeper insights.
This is where pretrained AI models play a pivotal role. Through the ArcGIS Living Atlas, users can access over 100 ready-to-use deep learning models purpose-built for GIS workflows – whether it’s extracting building footprints, detecting objects, or mapping land cover change. Models like Prithvi Weather & Climate (W&C) go even further, enabling advanced applications like regional weather forecasting.
These pretrained models put the power of AI into everyone’s hands. You don’t need to be a data scientist or train models from scratch. Just plug them into your workflows using out-of-the-box tools in ArcGIS Pro and ArcGIS Online and get high-quality results at scale.
Meet the Next Generation: Vision-Language Models
We’re entering a new era of AI – one where vision–language models can extract features directly from imagery using nothing but simple English prompts. This exciting new capability is making geospatial analysis more accessible and intuitive than ever.
While task-specific models will continue to play an important role, we’re introducing a new class of AI models to the ArcGIS ecosystem: vision–language models. Unlike the task-specific models built for a single purpose – such as detecting trees or segmenting roads – these models are true multi-taskers. They can interpret both imagery and language, and respond intelligently to natural language instructions.
Imagine uploading an aerial image and simply asking:
- “What do you see?” → Returns a descriptive caption.
- “Segment the lake” → Outlines the water body.
- “Classify these images into forest, urban, and agriculture” → Instantly categorizes them.
No model training. No labeling. Just prompt – and you’re ready to go!

Real Examples in Action
We’ve integrated several Vision-Language models directly into ArcGIS. Here’s a glimpse at what’s now possible:
Image Interrogation
Ask, “What do you see in this image?” and get back a full description of visible features—roads, rivers, buildings, clouds, vegetation, even man-made structures.
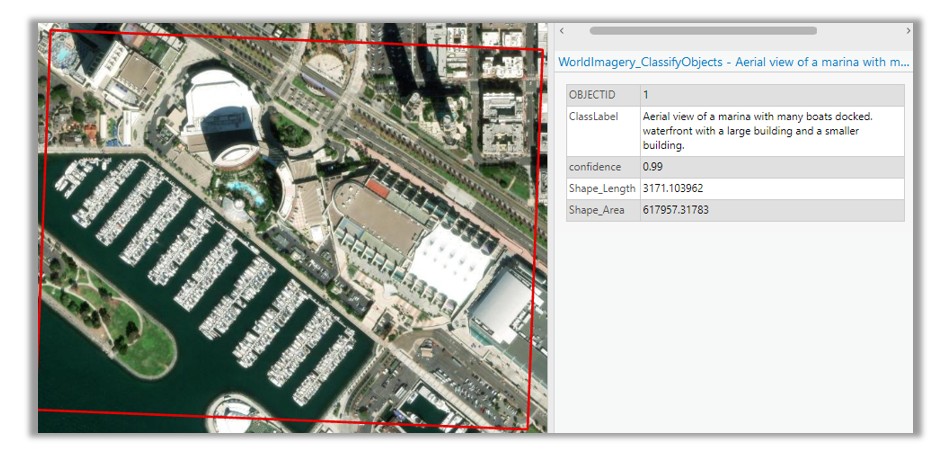
Vision-Language Context Based Classification
Prompt the model with labels like “damaged building,” “intact building,” “debris”, and it can classify image features accordingly. This can be especially useful in post-disaster scenarios.

Grounding DINO
Describe the features you’d like the model to detect, such as “solar panels” or “ships”, and the model returns spatially grounded detections in the form of GIS layers.

Zero-Shot Classification
The zero-shot classification models classify an entire image into one of the provided text labels. They use the model’s pre-trained knowledge of image and text relationships to classify images based on your provided class names, such as “flood”, “fire” or “landslide”.

Prompt-based Segmentation
With this model, you can segment features like lakes, agriculture zones, or flooded areas by simply asking. This makes it perfect for exploratory analysis or rapid mapping.

TextSAM
This model is great at extracting objects with clear boundaries and distinct shapes, such as cars, trees, buildings, etc. Prompt it with natural language – “round objects, oil tanks” – and it responds with pixel-accurate segmentation masks of oil tanks in the imagery.

Precision vs. Flexibility: Not Either-Or
You might be wondering: Should I use a task-specific model or a generalized one?
The answer: Both have their place.
- Task-specific models are precision tools – fast, accurate, and optimized for specific types of data (like multispectral or SAR imagery).
- Generalized vision-language models are more like Swiss Army knives – flexible, fast to deploy, and incredibly intuitive to use, though only with natural color imagery.
The key is to use the right tool for the task. When you need scalable, high-accuracy building extraction over an entire city – task-specific wins. When you’re quickly exploring imagery or asking ad-hoc questions – vision-language models shine.
We’re excited to bring this new class of AI models to the ArcGIS platform – and even more excited to see what you’ll build with them.
Curious to try them out? Explore the models in the ArcGIS Living Atlas or contact us to learn how to integrate generalized vision language models in your geospatial workflows.


Article Discussion: