Spatial data scientists and GIS analysts increasingly deal with massive, distributed datasets stored in cloud data lakes. While ArcGIS GeoAnalytics Engine brings powerful, scalable spatial analysis to Spark environments like Amazon EMR, many users still face challenges around finding, managing, and reusing spatial datasets efficiently in shared environments.
This is where the AWS Glue Data Catalog paired with GeoAnalytics Engine becomes increasingly valuable in a modern spatial data science workflow. As a centralized metadata repository, the Glue Data Catalog helps data science teams discover, organize, and manage the schema of their datasets stored in Amazon S3, RDS, Redshift, and more. When Spark on EMR is configured to use the AWS Glue Data Catalog for table metadata, you can:
- Get a unified view of data sources directly in your PySpark notebook – making it easier to discover, access, and analyze spatial data with varied geometry types (e.g., points, multipoints, linestrings, polygons) shared and managed across teams and projects.
- Ensure schema consistency for repeatable spatial analysis workflows.
- Automate dataset registration using crawlers or
.saveAsTable. - Instantly apply GeoAnalytics Engine’s SQL functions + tools on discoverable datasets within your PySpark notebook.
In this blog, we’ll show how you can leverage the AWS Glue Data Catalog with ArcGIS GeoAnalytics Engine running on your EMR cluster to streamline spatial data discovery and analytics workflow. Our example use case focuses on a county-level Covid-19 dataset from the United States, containing over 2.8 million records, to help understand outbreak patterns. As we explore this dataset, we’ll specifically walk you through the steps of:
- How to catalog your spatial data in AWS Glue.
- How to configure your EMR Cluster to use AWS Glue Data Catalog as an external metastore that can be accessed by GeoAnalytics Engine.
- How to discover, read, analyze, and write S3 tables using AWS Glue Data Catalog and GeoAnalytics Engine.
In the AWS Glue Data Catalog, metadata is organized into tables, where each table represents the structure and properties of a specific data source. You can populate the Data Catalog using a crawler, which automatically scans data sources and extracts metadata. Crawlers can connect to both AWS-native and external data sources. In this example, we’ll use Amazon S3 as our data source. The diagram below presents a high-level architecture that integrates Amazon S3, the AWS Glue Data Catalog, and ArcGIS GeoAnalytics Engine running on Amazon EMR.
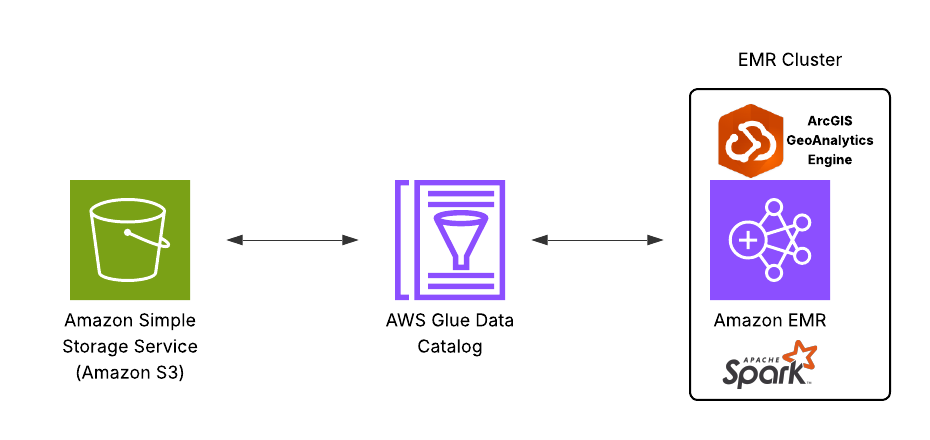
1. Catalog Your Data in AWS Glue
To catalog your data in S3 using AWS Glue Data Catalog:
- Have your data in S3 and an Identity and Access Management (IAM) role with access to both S3 and Glue.
- In the Glue Console, optionally create a database to organize your tables.
- Create a crawler, point it to your S3 path, assign the IAM role, and choose your target database that you just created.
- Configure it to run on demand or on schedule.
- After running the crawler, you’ll find the table metadata under the Tables section – ready for use with EMR, Glue jobs, Athena, and more.
Follow these steps as shown here, if needed:
2. Configure EMR Cluster to Use AWS Glue Data Catalog as External Metastore
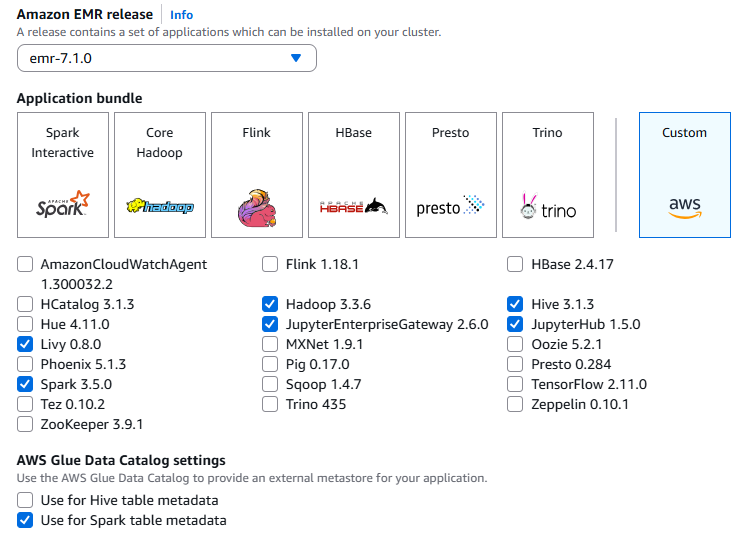
Navigate to Amazon EMR and click Create cluster. Next, follow this step-by-step workflow to install ArcGIS GeoAnalytics Engine in the cluster. To begin with, choose an appropriate Amazon EMR release and custom application bundle that are compatible with your version of the GeoAnalytics Engine distribution (see here).
By default, Spark on EMR uses the local Hive metastore, which is ephemeral – all metadata is lost when the cluster is terminated. Starting with EMR release 5.8.0, you can configure Spark to use the AWS Glue Data Catalog as its Hive-compatible metastore. Selecting “Use for Spark table metadata”, as shown below, lets Spark use the AWS Glue Data Catalog as its metastore, allowing your tables created with Spark SQL or DataFrames to be persistently stored and shared across clusters and other AWS services. “Use for Hive table metadata” does the same for Hives but does not affect Spark unless the Spark setting is also checked. You can enable both options to share table metadata across Spark, Hive, and other services.
As for the IAM permission, if you use the default EC2 instance profile, no further action is required. Because the AmazonElasticMapReduceforEC2Role managed policy that is attached to the EMR_EC2_DefaultRole allows all necessary AWS Glue actions. However, if you choose to specify a custom EC2 instance profile and permissions, follow the guideline here.
3. Discover, Read, Analyze, and Write S3 Tables Using AWS Glue Data Catalog and ArcGIS GeoAnalytics Engine
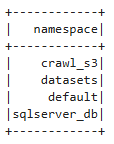
After you have successfully created the cluster, launch your Workspace (notebook) and attach it to the cluster. In your notebook cell, you can begin by listing all available Glue databases.
spark.sql("show databases").show()
Let’s set the active database for your Spark session to crawl_s3 (the one you created in the previous step by following the video demo) and discover what tables are within it.
spark.catalog.setCurrentDatabase("crawl_s3")
spark.sql("show tables").show()
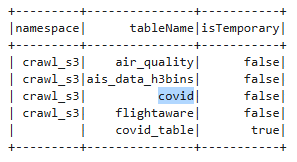
Suppose you’re interested in analyzing county-level Covid-19 case data stored in a table named covid. But before diving into the analysis, let’s take a short detour: what if you weren’t sure which tables under crawl_s3 actually contain geospatial data? Theoretically, there could be hundreds of tables under crawl_s3 database. While the Glue Catalog currently does not natively distinguish between spatial and non-spatial tables, you can add custom metadata to help with discovery. For example, you can tag spatial tables using table properties and here we’re doing this for our covid table (since it has some location information):
spark.sql("""
ALTER TABLE covid
SET TBLPROPERTIES (
'has_spatial' = 'true'
)
""")
This simple metadata tagging makes it easier to identify and manage spatial datasets at scale. Like this:
has_spatial = dict(spark.sql("SHOW TBLPROPERTIES `covid`").collect()).get("has_spatial")
print(f"has_spatial: {has_spatial}")
has_spatial: trueNow, let’s read and analyze data records from the covid table (via the Glue Catalog, rather than directly from S3) as a Spark DataFrame:
df = spark.sql("SELECT * FROM covid")
df.show()
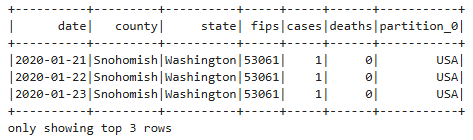
While reading from a Glue Catalog table is not inherently faster than a direct S3 read, it provides important advantages like automatic schema handling and partition awareness, which can improve usability and performance in real-world workflows. What that means is that the Data Catalog automatically captures and manages the schema of your data sources – including schema inference, evolution, and versioning – and you can update your schema and partitions in the Data Catalog using AWS Glue ETL jobs.
While the covid table includes county-level identifiers (like FIPS codes), it does not contain actual geometry data required for spatial analysis. To enable mapping and spatial operations, first we need to enrich this dataset with geospatial features. For that, using ArcGIS GeoAnalytics Engine, we load a USA Census County feature service as a Spark DataFrame and then using Spark SQL we perform the following steps:
- Perform an inner join between Covid-19 and County tables on the FIPS code.
- Extract year and month separately from the date column using YEAR() and MONTH() functions, enabling temporal aggregation at the monthly level.
- Aggregate Covid-19 data using SUM(cases) and SUM(deaths) by county, state, month, and year to get the total number of reported cases and deaths, respectively, for each county per month.
- Convert the geometry column
shapeto Well-Known Binary (WKB) format using the ST_AsBinary function from the GeoAnalytics Engine. This step is necessary because AWS Glue does not natively support geometry or geography spatial types. Hence, we use standard text or binary formats to represent our spatial data. Converting toWKBallows the aggregated data to be cataloged in Glue and later interpreted correctly by the GeoAnalytics Engine for geospatial queries and analysis.
URL = "https://services.arcgis.com/P3ePLMYs2RVChkJx/arcgis/rest/services/USA_Census_Counties/FeatureServer/0"
spark.read.format("feature-service").load(URL).select("FIPS", "NAME", "shape").createOrReplaceTempView("county")
df = spark.sql("""
SELECT
county,
state,
YEAR(date) AS year,
MONTH(date) AS month,
SUM(cases) AS total_cases,
SUM(deaths) AS total_deaths,
ST_asBinary(shape) AS WKB
FROM covid
INNER JOIN county
ON covid.fips = county.FIPS
GROUP BY
county,
state,
YEAR(date),
MONTH(date),
shape
""")
df.show()
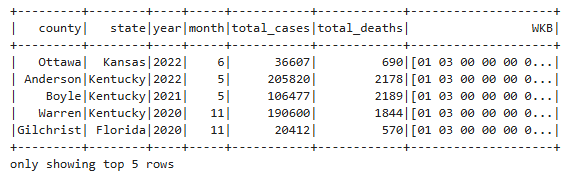
At this point, you can optionally export the resulting DataFrame to ArcGIS Online as a hosted feature service layer and then create a time slider map to analyze the Covid-19 outbreak patterns across U.S. counties.
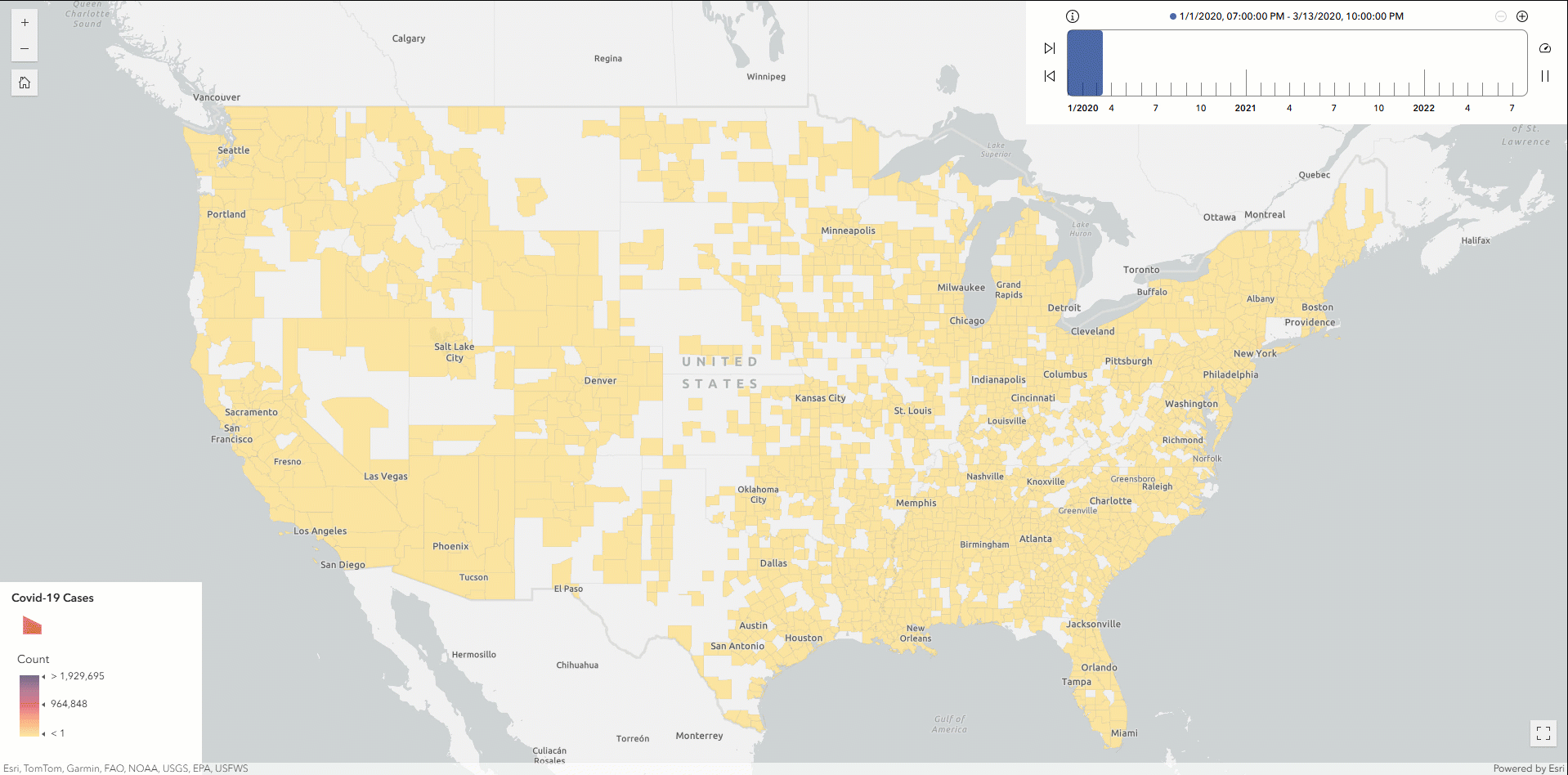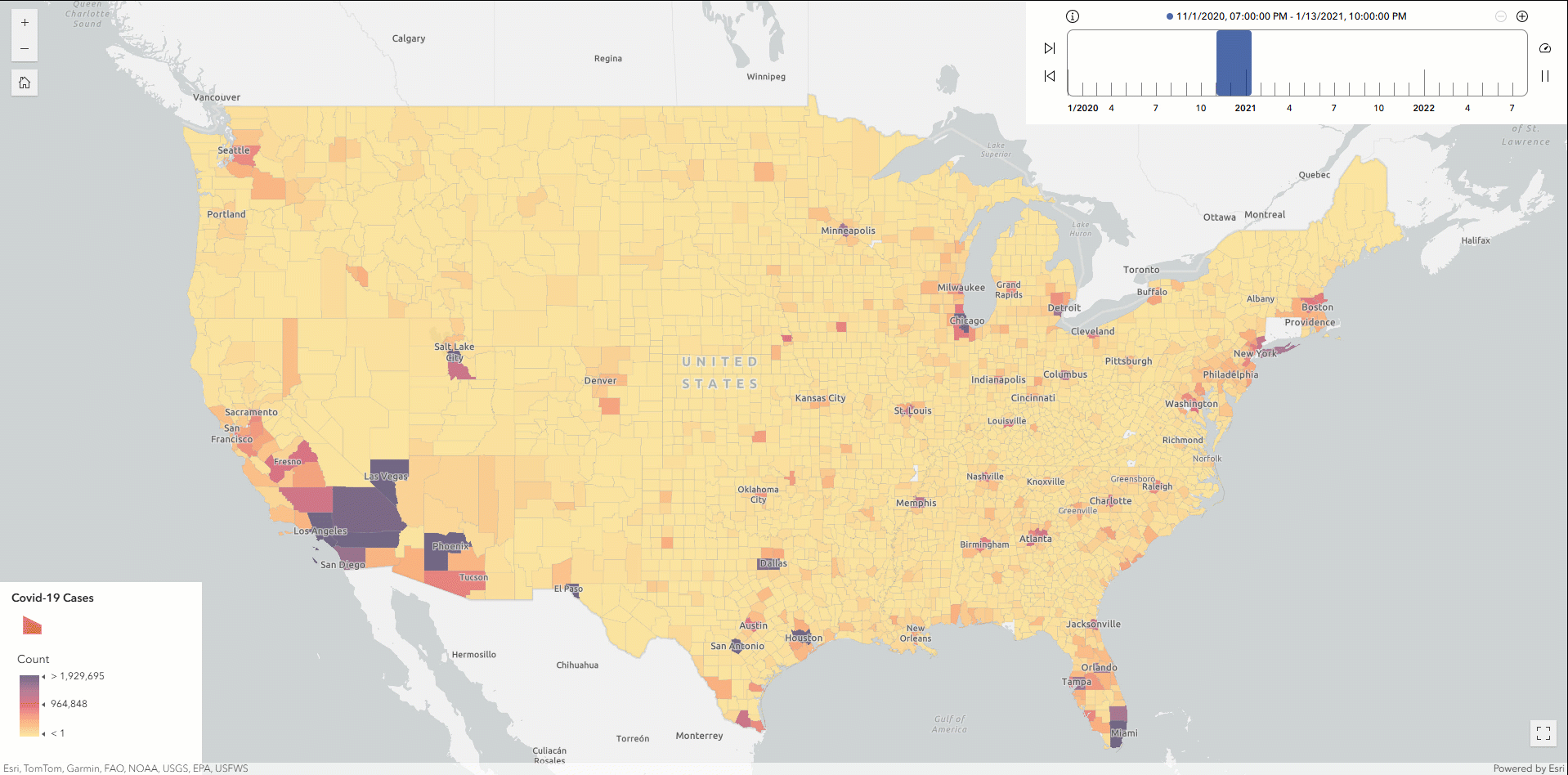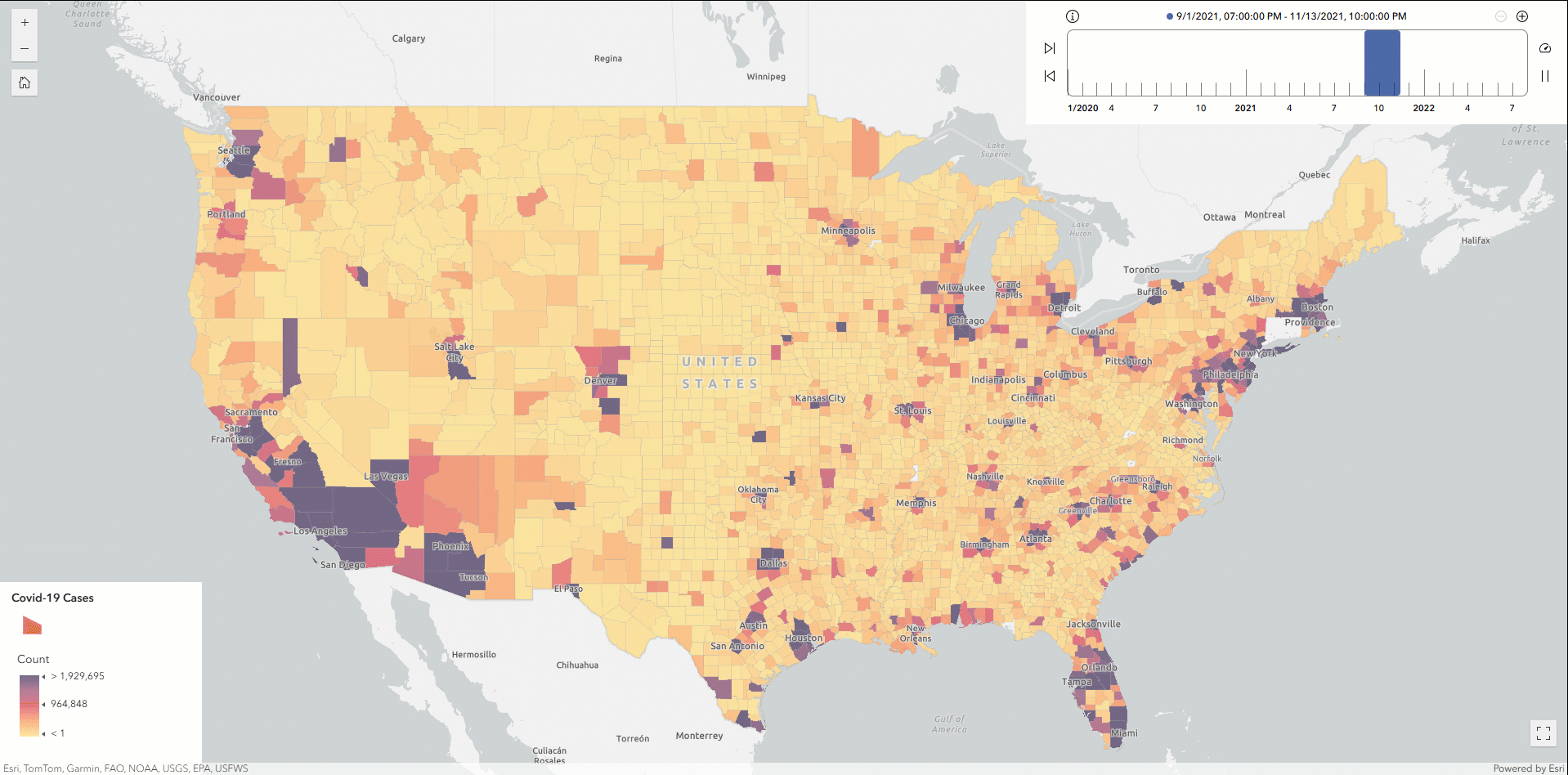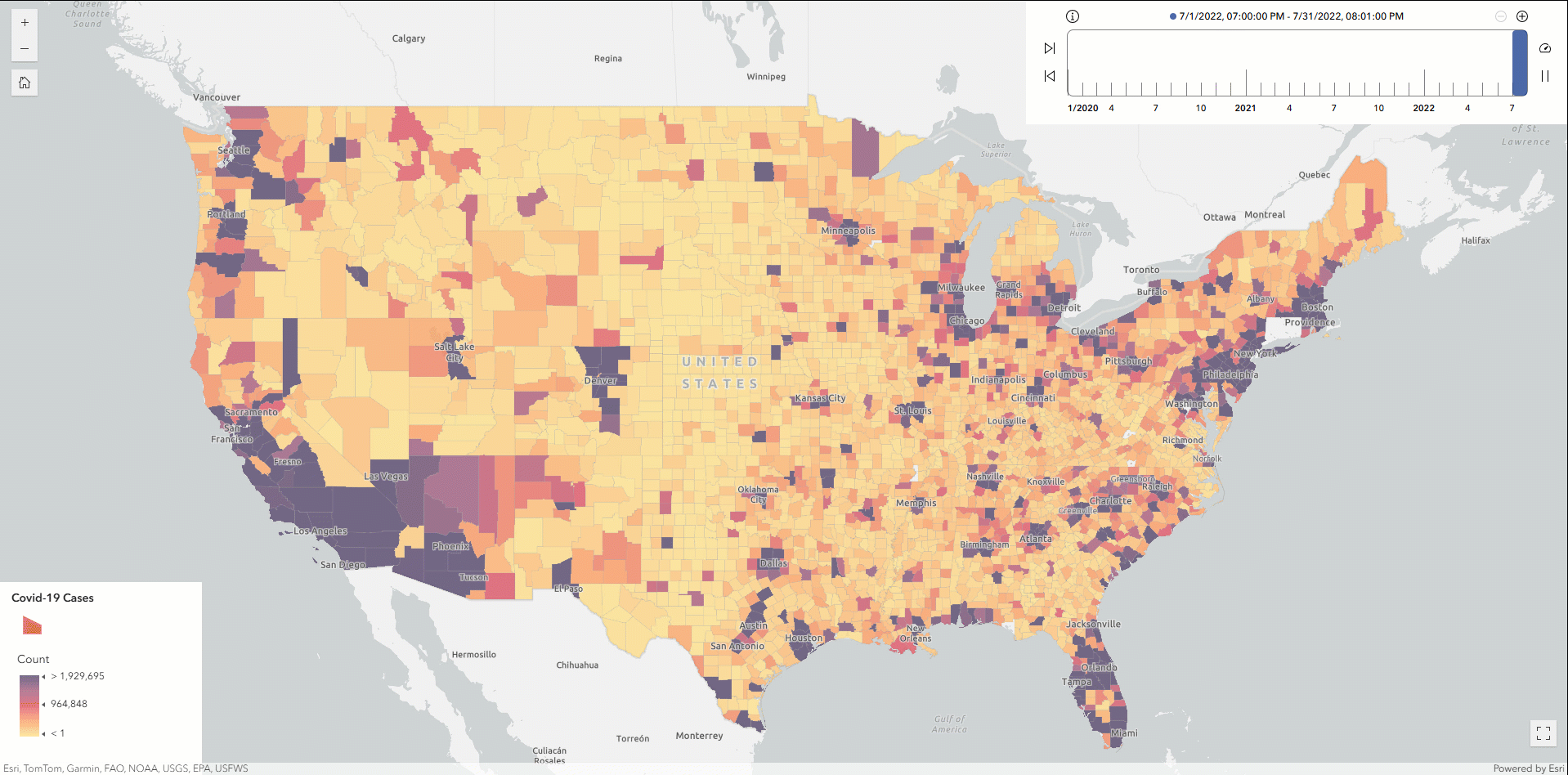
Finally, let’s write the DataFrame as parquet format to a designated S3 location and register it as a table named Covid_ByCounty. This approach enables the dataset to be cataloged as a standard binary column while retaining spatial information. By registering the output in the AWS Glue Data Catalog, the geospatial data becomes immediately accessible for future querying and analysis using tools like GeoAnalytics Engine or Amazon Athena—without needing to reload from the original S3 source.
output_path = "s3://ga-engine/data_for_glue_cataloging/Outputs/"
df.write.format("parquet") \
.mode("overwrite") \
.option("path", output_path) \
.saveAsTable("Covid_ByCounty")
You can verify the registration by listing your Glue database tables:
spark.sql("show tables").show()
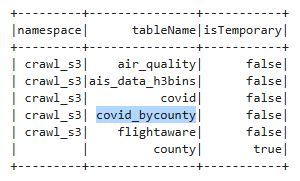
By writing “geo-informed” DataFrames to S3 and registering them in the AWS Glue Data Catalog, spatial data teams gain centralized schema management and seamless interoperability across AWS analytics services. This approach enhances discoverability, reusability, and governance, making your geospatial and non-geospatial data workflows more scalable and collaborative.


Article Discussion: