Fall 2004
Fall 2004 |
|||||||
|
|
|||||||
USGS EROS Data Center Produces Seamless Hydrologic Derivatives With GIS |
|||
|
By Sandra K. Franken, Environmental Scientist, USGS/EROS Data Center
In 2000, scientists and hydrologists at the U.S. Geological Survey (USGS) Earth Resources Observation Systems (EROS) Data Center (EDC) met to determine the feasibility of a nationwide seamless database that would provide better drainage basin boundaries and provide modelers with consistent digital elevation model (DEM)-derived layers for use in basin characterization. Because of the magnitude and scope of the proposed database, a collaborative arrangement of cooperators was formed to produce a seamless database of topographically derived layers. The cooperators consisted of EDC in Sioux Falls, South Dakota; the National Severe Storms Laboratory in Norman, Oklahoma; and the USGS Water Resources Discipline in Sacramento, California. The efforts of the cooperators formed the first version of the Elevation Derivatives for National Applications (EDNA), a multilayered, nationally seamless database. After the arrangement of cooperators was formed, researchers at EDC began investigating hardware and GIS software that would be capable of creating and housing a multiterabyte seamless nationwide hydrologic derivative database composed of numerous topographically derived layers. Although many of the tools used in the EDNA development had been implemented in standard GIS software and used for small to moderate applications, utilization of the tools for a project of this size had not been attempted prior to the development of EDNA.
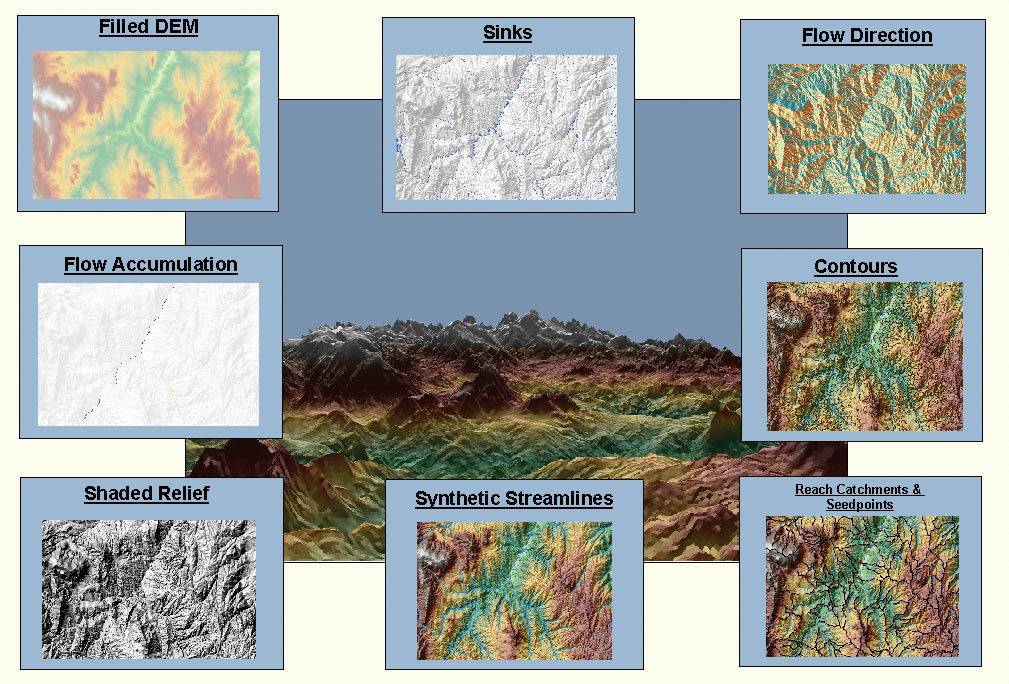
The development of EDNA required intense planning, research, production time, and hardware storage capabilities. EDNA was planned as a three-stage project that spanned several years. Stage I, which began in 2000 and was completed in 2002, encompassed the creation of the topographically derived data by the project cooperators in Norman, Oklahoma, and Sacramento, California. The data was then forwarded to EDC where a methodology was developed that provided accurate and efficient data processing standards to piece the data together into a national seamless database. The meticulous flow process provided accurate management of the terabytes of data received from the cooperators. In Stage II, cooperators provided field checks on the watershed delineations produced in Stage I. Problem areas were identified and corrected in Stage III of the project. The outcome of the three-stage project was a hydrologically conditioned DEM implemented into the seamless database. Creating the national hydrologic derivatives in one large piece was not yet feasible because of the size of the National Elevation Dataset (NED), which formed the basis for the EDNA database. NED exceeded 60 gigabytes of disk space for the conterminous United States alone. Therefore, the size of the project required a unique solution that involved accessing ArcGIS to create the hydrologic derivative database. The suite of ArcGIS applications and extensions, including ArcInfo, ArcEditor, ArcGIS Spatial Analyst, ArcSDE, ArcIMS, and ArcGIS 3D Analyst, was utilized to solve the problem of creating such a large seamless database for the United States. The processes consisted of a set of ARC Macro Language (AML) scripts that consistently produced replicable results. The first version of EDNA was developed by individually processing each cataloging unit, which is a spatial element of the hydrologic units of the United States. The cataloging unit is a geographic area representing part or all of a surface drainage basin, a combination of drainage basins, or a distinct hydrologic feature. The cataloging units were chosen as the processing units not only because they subdivided the NED into smaller, more manageable units but also because these units were "hydrologically based." The boundaries of the cataloging units approximated hydrologic divides, which made the task of assembling 2,108 cataloging units back into a seamless database easier. Utilizing the cataloging unit as the "cookie cutter" for extracting elevation data, the processes for creating EDNA data began. The NED data was extracted using buffered cataloging unit polygons and projected into the USA Contiguous Albers Equal Area Conic USGS projection at a 30-meter resolution. Using an algorithm to locate and fill all depressions or sinks where there was no flow from pixel to pixel, the projected and clipped DEM was filled so that synthetic flow would not be stopped by spurious sinks. The direction of flow from each pixel to its steepest downslope neighboring pixel and the number of upstream pixels that flow to a specific pixel were then derived from the filled DEM. An initial derivation of synthetic streamlines was made by thresholding the flow accumulation at 5,000 pixels (approximately 2 square miles). Corresponding drainage basins for each reach in the synthetic streamlines layer were derived. Additionally, the flow accumulation was adjusted to account for upstream drainage. The streams and drainage basins were attributed with a Pfafstetter code, which is a numbering system for efficient upstream and downstream tracing of basins and stream networks. The advantage of this process was that drainage could be characterized at any given point within the drainage basins, thereby eliminating the need to process large volumes of raster data each time the delineation was run. Drainage areas upstream or downstream from any location can be accurately traced, facilitating flood analysis investigations, pollution studies, and hydroelectric power generation. The EDNA database not only contains topographically derived streamlines but also 11 raster grids and 18 vector coverages for each cataloging unit. The GIS layers include flow accumulation, flow direction, slope, gradient, catchments, and contours. EDNA data was developed for each of the 2,108 cataloging units, resulting in more than 61,000 GIS layers within the contiguous United States alone—billions of pixels. This vast amount of seamless data required adequate storage for not only the data itself but also the intense processes required to create it. The data and processes were housed on a Sun Ultra-Enterprise server at EDC where researchers had ready access to the terabytes of EDNA data. However, to facilitate nationwide analyses and Web-based applications, the first version of the EDNA database was loaded and managed with Oracle table spaces through the application of ArcSDE. The loading processes for vector coverages were fully automated using AML. Visual Basic for Applications procedures resulting from a cooperative research and development agreement with Esri were used to load and mosaic the EDNA raster layers. Pyramids, which allow for faster viewing at different spatial scales, were built, statistics were created, and versioning allowed the end user to access, view, and analyze the database. EDNA can now be viewed in its full seamless fashion via ArcIMS to trace stream networks, determine mean annual stream flow and flow accumulated layers, and delineate watersheds (edna.usgs.gov and gisdata.usgs.net/website/lakemich). Work funded through the Department of Energy's Idaho National Engineering and Environmental Laboratory provided a nationwide climatological application of the aforementioned procedures. This application that utilized the Stage I EDNA data was completed in 2003. EDNA is well suited to many other applications that can be viewed at edna.usgs.gov. In addition to the standard ArcInfo processes used to create the EDNA database, a unique flyby of the United States was created with the 3D Analyst ArcScene application. The nationwide flyby was completed on a PC with an OpenGL video card, 1.5 gigahertz, and a gigabyte of memory to sustain the necessary 3D application. The flyby can be viewed at gisdata.usgs.gov/topographic. For more information, contact Sandra Franken, environmental scientist, USGS EROS Data Center, Sioux Falls, South Dakota (e-mail: franken@usgs.gov, tel.: 605-594-2634). Any use of trade, product, or firm names in this article is for descriptive purposes only and does not imply endorsement by the U.S. government. |
 Increasingly, many local, state, and federal agencies mandated to manage water resources are finding that their needs are not being met by existing digital data sets. Current national coverage of digital data sets, such as drainage basin boundaries and consistent elevation-derived parameters, does not exist or is not of a suitable scale or consistency to allow management of small or midsize watersheds. This problem has become more significant as the management of water resources, both in terms of quantity and quality, is becoming more and more based on the watershed scale.
Increasingly, many local, state, and federal agencies mandated to manage water resources are finding that their needs are not being met by existing digital data sets. Current national coverage of digital data sets, such as drainage basin boundaries and consistent elevation-derived parameters, does not exist or is not of a suitable scale or consistency to allow management of small or midsize watersheds. This problem has become more significant as the management of water resources, both in terms of quantity and quality, is becoming more and more based on the watershed scale.