Summer 2009
Summer 2009 |
|||||||
|
|
|||||||
Process Models and Next-Generation Geographic Information Technology |
|||||
|
By Paul M. Torrens
The next generation of geographic information systems will be driven by process models. These are usually composed of algorithms and heuristics that will act on users' requests for the GIS to perform some service for them, connect to digital networks to contextualize those requests, and interact seamlessly with other databases and processes to achieve users' goals. Alternatively, process models may be used as a synthetic representation of system parts to build artificial phenomena "in silico" that can be subjected to experimentation and what-if scenario building in ways that are not possible "on the ground." Geoprocessing has been featured with increasing priority in GIS for some time, and conventional GIS already relies on geoprocessing for spatial analysis and data manipulation. Process models represent an evolution from these existing technologies, catalyzed by artificial intelligence that takes traditional GIS operations into the world of dynamic, proactive computing on a semantic Web of interconnected data and intelligent software agents. Imagine, for example, building a representation of the earth's boundary layer climate in GIS, but also being able to run dynamic weather patterns, storms, and hurricanes over that data, using climate models that sit in a supercomputing center on another continent. This article charts the development of process models in the geographic information sciences and discusses the technologies that have shaped them from the outside in. In addition, it explores their future potential in allying next-generation GIS to the semantic Web, virtual worlds, computer gaming, computational social science, business intelligence, cyberplaces, the emerging "Internet of Things," and newly discovered nanospaces. BackgroundMuch of the innovation for process models in the geographic sciences has come from within the geographic information technology community. Geoprocessing featured prominently in the early origins of online GIS, where server-based GIS delegated much of the work that a desktop client would perform to the background, hidden from the user. Interest in geoprocessing has resurfaced recently, largely because of increased enthusiasm for online cartography and expanding interest in schemes for appropriating, parsing, and reconstituting diverse data sources from around the Web into novel mashups that lean on application programming interfaces—interfaces to centralized code bases—that have origins in search engine technology.
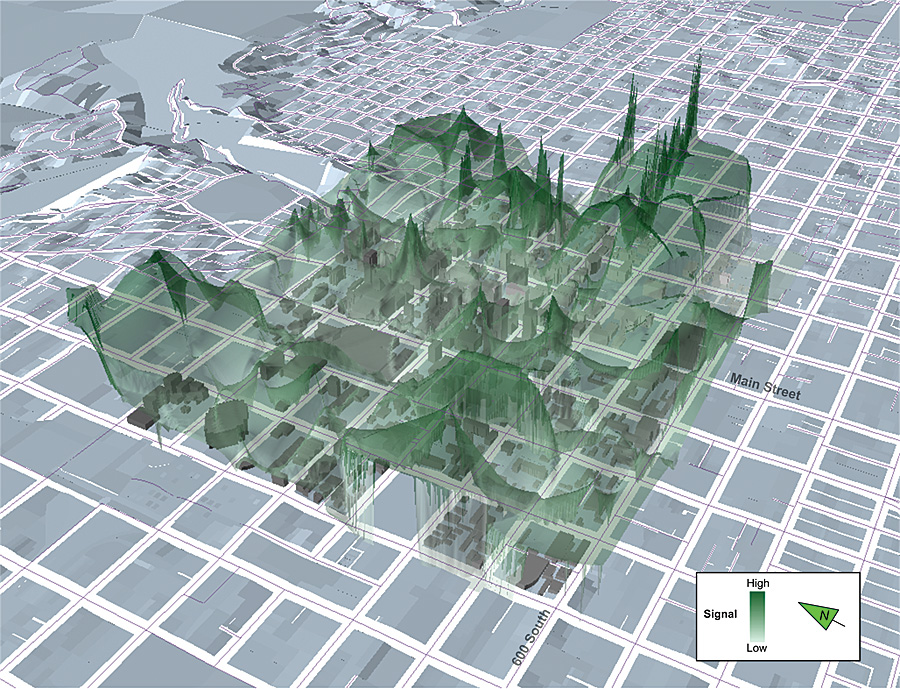
Concurrently, many scholars in the geographic information science community have been developing innovative methods for fusing representations of space and time in GIS. This has seen the infusion of schemes from time geography into spatial database and data access structures to allow structured queries to be performed on data's temporal, as well as spatial, attributes. Time geography has also been used in geovisualization, as a method for representing temporal attributes of datasets spatially, thereby allowing them to be subjected to standard spatial analysis. Much of this work has been based around a move toward creating cyberinfrastructure for cross-disciplinary research teams, and significant advances have been made in developing technologies to fuse GIS with real-time data from the diverse array of interconnected sensors and broadcast devices that now permeate inventory systems, long-term scientific observatories, transportation infrastructure, and even our personal communication systems. In parallel, work in spatial simulation has edged ever closer toward a tight coupling with GIS, particularly in high-resolution modeling and geocomputation using cellular and agent-based automata as computational vehicles for animating objects through complex adaptive systems. Automata are, essentially, empty data structures capable of processing information and exchanging it with other automata. Simulation builders often turn to GIS routines in search of algorithms for handling the information exchange between automata, and over time, a natural affinity between the two has begun to develop into a mutually influential research field often referred to as geosimulation. Much of the work in developing process models is finding its way into GIS from outside fields, however, and developments in information technology for the Web—and for handling geographic data on the Web—have been particularly influential. A massive growth in the volume and nature of data in which we find our lives and work enveloped has catalyzed a transition from a previous model of the Web to a newer-generation phase. The Web remains fundamentally the same in its architecture, but the number of applications and devices that contribute to it has swelled appreciably, and with this shift, a phase change has taken place, instantiating what is now commonly referred to as Web 2.0. The previous iteration of Web development was centered on static, subscription-based content aggregated by dominant portals such as AltaVista, AOL, Excite, HotBot, Infoseek, Lycos, and Yahoo! By comparison, much of the current generation model for the Web is characterized by user-generated content (blogs, Twitter tweets, photographs, points of interest, even maps) and flexible transfers between diverse data sources. Moreover, these varied data streams interface seamlessly over new interoperable database and browser technologies and are often delivered in custom-controlled formats directly to browsers or handheld devices via channels such as Really Simple Syndication (RSS). This takes place dynamically, updating in near real time as the ecology of the Web ebbs and flows. Enveloping these developments has been a groundswell in the volume of geographic data fed to the Web. In many ways, Web 2.0 has been built on the back of the GeoWeb that has formed between growing volumes of location-enabled devices and data that either interface with the Web in standardized exchanges (uploading geotagged content to online data warehouses, for example) or rely on the Web for their functionality (as in the case of alternative positioning systems that triangulate their location based on wireless access points). The reduction in the cost of geographic positioning technologies led to the massive infusion of location-aware technology into cameras, phones, running shoes, and cars; atop bicycle handlebars; and in clothing, pets, handheld gaming devices, and asset-tracking devices on the products that we buy in supermarkets. Devices all over the world began to sense and communicate their absolute and relative positions, allowing, first, the devices to be location tagged; second, those tags to become a significant medium for organizing, browsing, searching, and retrieving data; and, third, their relative geography to become the semantic context that ascribes to those objects (and their users) information. Indeed, for many online activities, maps and GIS have become the main portal to the Web. Semantic intelligence is driving the next evolution of the Web, characterized by the use of process models (usually referred to as software agents or Web services) as artificial intelligence that can reason about the meaning of data that courses through Internet and communication networks. A slew of ontological schemes—methods for classifying data and its relationships—provides the scaffolding that supports semantic reasoning online. Geography and location ontology is an important component of online semantics, allowing processes to not only know where something is in both network space and the tangible geography of the real world but also to reason about where it might have been, where it might go and why, whether that is usual or unusual behavior, what might travel with it, what might be left behind, what activities it might engage in along the way or when it reaches its destination, and what services might be suggested to facilitate these activities. Often, these may be location-based services that make use of the geographic position of a device, its user, or the local network of related devices, or they may make use of the network to deliver "action at a distance" to enrich a user's local experience, by connecting the user to friends across the world, for example. Process models have also been developed in other information systems. Much of the potential for advancing geographic information technology stems from the ability of GIS to interface with other processes and related informatics through complementary process modeling schemes. The early precursors of this interoperability are already beginning to take shape through the fusion of GIS and building information models (BIMs). BIMs offer the ability of urban GIS to focus attention on a much finer resolution than ever, to the scale of buildings' structural parts and their mechanical systems. GIS allows BIMs to consider the role of the building in a larger urban, social, geological, and ecosystem context. When process models are added to the mix, the complementary functionality expands even farther. Consider, for example, the uses of a GIS that represents the building footprints of an entire city but can also connect to building information models to calculate the energy load of independent structures for hundreds of potential weather scenarios, or BIMs that can interact with an earthquake simulation to test building infrastructural response to subsurface deformation in the bedrock underneath, using cartography to visualize cascading envelopes of projected impact for potential aftershocks. Virtual WorldsMany advocates of the semantic Web envision a massive dynamic system of digitally networked objects and people, continuously casting "data shadows" with enough resolution and fidelity to constitute a virtual representation of the tangible world. These virtual worlds are already being built, and many people and companies choose to immerse themselves in online virtual worlds and massively multiplayer online role-playing gaming (MMORPG) environments for socializing, conducting business, organizing remotely, collaborating on research projects, traveling vicariously, and so on. Here, process models are also driving advances in technology. Process models from computer gaming engines have been ported to virtual worlds, to populate them with automated digital assistants and synthetic people that behave and act realistically and can engage with users in the game world in much the same way that social interactions take place in the real world. Virtual worlds have been coupled with realistic, built and natural environment representations constructed using geometry familiar to GIS. The current generation of process models for MMORPG environments is relatively simple in its treatment of spatial behavior, but rapid advances are being made in infusing them with a range of behavioral geographies and spatial cognitive abilities that will enable more sophisticated spatial reasoning to be included in their routines.
Gaming is just one application of process models in virtual worlds. The actions and interactions of synthetic avatars representing real-world people can be traced with perfect accuracy in virtual worlds because they are digital by their very nature, and often, that data may be associated with the data shadows that users cast from their real-world telecommunications and transactional activities in the tangible world. Virtual worlds are seen by many as terra novae for new forms of retailing, marketing, research, and online collaboration in which avatar representations of real people mix with process models that study them, mimic missing components of their synthetic physical or social environments, mine data, perform calculations, and reason about their actions and interactions. Code SpaceAspects of the semantic Web may seep into the real world, from cyberspace to "meatspace." In many ways, the distinction between the two has long ago blurred, and for many of us, our lives are already fully immersed in cyberplaces that couple computer bits and tangible bricks, and we find much of our activity steeped in flows of information that react to our actions and often shape what we do. Geographers have begun to document the emergence of what we might term a "code space," a burgeoning software geography that identifies us and authenticates our credentials to access particular spaces at particular times and regulates the sets of permissions that determine what we might do, and with whom, while we are there. Commercial vehicle traffic for interstate commerce, commuter transit systems, and airports are obvious examples of code space in operation in our everyday lives. Mail systems transitioned fully to coded space a long time ago: for parcel delivery services, almost every object and activity can be identified and traced as it progresses through the system, from collection to delivery on our doorstep. Other code spaces are rapidly moving to the foreground: patients, doctors, and supplies are being handled in a similar fashion in hospitals. Goods in supermarkets and shopping malls are interconnected through intricate webs of bar codes, radio-frequency identification (RFID) tags, and inventory management systems that reason about their position in a network of stores and even the supply geography of individual packets on a shelf. Similarly, transactions may be tagged at the point of sale and associated uniquely to customers using loyalty, debit, and credit cards that also link customers to their neighbors at home and similar demographic groupings in other cities, using sophisticated geodemographic analyses. The influence between location-aware technology and sociology is also beginning to reverse. Other code spaces facilitate the emergence of "smart mobs" or "flash mobs," social collectives organized and mediated by Internet and communications technologies: text messaging, instant messaging, and tweeting, for example, for the purposes of political organization; social networking; or, as is often the case, simple fun. The Internet of ThingsIn technology circles, objects in a code space are referred to as "spimes," artifacts that are "aware" of their position in space and time and their position relative to other things; spimes also maintain a history of this location data. The term spime has arisen in discussions about the emergence of an Internet of Things, a secondary Internet that parallels the World Wide Web of networked computers and human users. The Internet of Things is composed of (often computationally simple) devices that are usually interconnected using wireless communications technologies and may be self-organizing in formation. While limited individually, these mesh networks adopt a collective processing power that is often greater than the sum of its parts when their independent process models are networked as large "swarms" of devices. Moreover, swarm networks tend to be very resilient to disruption, and their collective computational and communication power often grows as new devices are added to the swarm. Networks of early-stage spimes (proto-spimes) of this kind have already been developed using, for example, microelectromechanical systems (MEMS), which may be engineered as tiny devices that are capable of sensing changes in electrical current, light, chemistry, water vapor, and so on, in their immediate surroundings. When networked together in massive volumes, they can be used as large-geography sensor grids for earthquakes, hurricanes, and security, for example. Sensor readings can be conveyed in short hops between devices over large spaces, back to a human observer or information system for analysis. MEMS often contain a conventional operating system and storage medium and can thus also perform limited processing on the data that they collect, deciding, for example, to take a photograph if particular conditions are triggered, and geotagging that photograph with a GPS or based on triangulation with a base station. Geodemographics and Related Business IntelligenceThe science and practice of geodemographics are concerned with analyzing people, groups, and populations based on tightly coupling who they are with where they live. The who in this small formula can provide information about potential debtors', customers', or voters' likely economic profile, social status, or potential political affiliation on current issues, for example. The where part of the equation is tasked with identifying what part of a city, postal code, or neighborhood those people might reside in, for the purposes of allying them to their neighboring property markets, crime statistics, and retail landscapes, for example. Together, this allows populations and activities to be tagged with particular geodemographic labels or value platforms. These tags are used to guide a host of activities, from drawing polling samples to targeting mass mailing campaigns and siting roadside billboards. The dataware for geodemographics traditionally relied on mashing up socioeconomic data collected by census bureaus and other groups with market research and point-of-sale data gathered by businesses or conglomerates. Traditionally, the science has been relatively imprecise and plagued with problems of ecological fallacy in relying on assignment of group-level attributes to individual-level behavior. Because of early reliance on data from census organizations, which aggregate returns to arbitrary geographic zones, the spatial components of geodemographics have also suffered from problems of modifiable areal units (i.e., there are an almost infinite number of ways to delineate a geographic cluster). Data is often collected for single snapshots in time and is subject to serious problems of data decay; households, for example, may frequently move beyond or between lifestyles or trends, without adequate means in the geodemographic classification system to capture that transition longitudinally. Process models could change geodemographics. When users browse the Web, their transactions and navigation patterns, the links they click, and even the amount of time that their mouse cursor hovers over a particular advertisement can be tracked and geocoded uniquely to their machine. Users' computers can be referenced to an address in the Internet protocol scheme, which can be associated to a tangible place in the real world using reverse geocoding. Along retail high streets and in shopping malls, customers now routinely yield a plethora of personal information in return for consumer loyalty cards, for example, or share their ZIP Codes and phone numbers at the point of sale, in addition to passively sharing their names when using credit or debit cards. By simply associating an e-mail address to this data, it is relatively straightforward, in many cases, to cross-reference one's activity in the tangible world with one's data shadow in cyberspace. Developments in related retail intelligence, business analytics, inferential statistics, and geocomputing have increased the level of sophistication with which data can be processed, analyzed, and mined for information. This allows the rapid assessment of emerging trends and geodemographic categories. Process models are even coded into the software at cash registers in some instances. Much of this technology is allied to spimes and code spaces. Technologies based around RFID and RFID tagging, initially designed for automated stock taking in warehouses and stores, are now widely embedded in products, cards (and therefore wallets), and the environment with such pervasiveness that they enable widespread activity and interaction tracking, particularly within a closed environment such as a supermarket. Coupled to something like a customer loyalty card, these systems allow for real-time feeds of who is interacting (or not) with (not just buying, but handling, or even browsing) what products, where, when, with what frequency, and in what sequences. The huge volumes of data generated by such systems provide fertile training grounds for process models. The increasing fusion of mobile telecommunication technologies with these systems opens up a new environment for coupling process models to mobile geodemographics. This is a novel development for two main reasons. First, it creates new avenues of inquiry and inference about people and transactions on the go (and associated questions and speculations regarding where they may have been, where they might be going, with whom, and to do what). Second, it allows geodemographic analysis to be refined to within-activity resolutions. This has already been put to use in the insurance industry, for example, to initiate pay-as-you-go vehicle coverage models, using GPS devices that report location information to insurance underwriters. Mobile phone providers have also experimented with business models based around location-based services and location-targeted advertising predicated on users' locations within the cell-phone grid, and groups have already begun to experiment with targeting billboard and radio advertising to individual cars based on similar schemes. New GIS schemes based around space-time process models and events are well positioned to interact with these technologies. NanosystemsWhen spimelike devices are built at very small geographies, capable of sensing and even manipulating objects at exceptionally fine scales, they become useful for nanoengineering. In recent years, there has been a massive fueling of interest in nanoscale science and development of motors, actuators, and manipulators at nanoscales. With these developments have come a veritable land grab and gold rush for scientific inquiry at hitherto relatively underexplored scales: within the earth, within the body, within objects, within anything to be found between 1 and 100 nanometers. Geographers missed out on the last bonanza at fine scales and were mostly absent from teams tasked with mapping the genome. The cartography required to visually map the genome is trivial and the processes that govern genomic patterns are completely alien to most geographers' skill sets, so their exclusion from these endeavors is understandable. The science and engineering surrounding nanotechnology differ from this situation, however, in that they are primarily concerned with spatiotemporal patterns and processes and the scaling of systems to new dimensions. These areas of inquiry are part of the geographer's craft and fall firmly within the domain of geographic information technologies. Process models with spatial sensing and semantic intelligence could play a vital role in future nanoscale exploration and engineering. Computational Social ScienceGeographic process models also offer tremendous benefits in supporting research and inquiry in the social sciences, where a new set of methods and models has been emerging under the banner of computational social science. Computational social science, in essence, is concerned with the use of computation—not just computers—to facilitate the assessment of ideas and development of theories for social science systems that have proved to be relatively impenetrable to academic inquiry by traditional means. Usually, the social systems are complex and nonlinear and evolve through convoluted feedback mechanisms that render them difficult or impossible to analyze using standard qualitative or quantitative analysis. Computational social scientists have, alternatively, borrowed ideas from computational biology to develop a suite of tools that will allow them to construct synthetic social systems within a computer, in silico, that can be manipulated, adapted, accelerated, or cast on diverging evolutionary paths in ways that would never be possible in the real world. The success of these computational experiments relies on the ability of computational social science to generate realistic models of social processes, however, and much of the innovation in these fields has been contributed by geographers because of their skills in leveraging space and spatial thinking as a glue to bind diverse cross-disciplinary social science. Much of computational social science research involves simulation-building. To date, the artificial intelligence driving geography in these simulations has been rather simplistic, and development in process models offers a potential detour from this constraint. Moreover, computational social science models are often developed at the resolution of individual people and scaled to treat massive populations of connected "agents," with careful attention paid to the social mechanisms that determine their connections. This often requires that large amounts of data be managed and manipulated across scales, and it is no surprise that most model developers turn to GIS for these tasks. Connections between agent-based models and GIS have been mostly formulated as loose couplings in the past, but recent developments have seen functionality from geographic information science built directly into agent software architectures, with the result that agents begin to resemble geographic processors themselves, with realistic spatial cognition and thinking. These developments are potentially of great value in social science, both in providing new tools for advanced model building and in infusing spatial thinking into social science generally. At the same time, developments in agent-based computing have the potential to feed back into classic GIS as architectures for reasoning about and processing human environment data. PrologueThis is a wonderful time to be working with or developing geographic information technologies, at the cusp of some very exciting future developments that will bring GIS farther into the mainstream of information technology and will infuse geography and spatial thinking into a host of applications. Of course, some potential sobering futures for these developments should be mentioned. As process models are embedded in larger information, technical, or even sociotechnical systems, issues of accuracy, error, and error propagation in GIS become even more significant. Ethical issues surrounding the use of fine-grained positional data also become more complex when allied with process models that reason about the significance or context of that data. Moreover, the reliability of process models as appropriate representations of phenomena or systems must come under greater scrutiny. About the AuthorDr. Paul M. Torrens is an associate professor in the School of Geographical Sciences at Arizona State University and director of its Geosimulation Research Laboratory. His work earned him a Faculty Early Career Development Award from the U.S. National Science Foundation in 2007, and he was awarded the Presidential Early Career Award for Scientists and Engineers by President George W. Bush in 2008. The Presidential Early Career Award is the highest honor that the U.S. government bestows on young scientists; Torrens is the first geographer to receive the award. More InformationFor more information, contact Dr. Paul M. Torrens, Arizona State University (e-mail: torrens@geosimulation.com). |
 Much of the inner workings of geographic information systems is organized around data models: computational structures (rasters and vectors are common variants) that determine how GIS stores, organizes, and displays various types of information for different purposes. Put simply, data models treat the world in terms of objects that represent entities and their related attributes. In GIS, there is usually no dedicated model of the processes that govern dynamics, adaptation, and evolution of a system. For many years, GIS has advanced the potential for unifying representations of entities and processes, and recently, the long-standing promise of consociating the two is beginning to be realized, enabling a burgeoning paradigm shift to a new style of GIS.
Much of the inner workings of geographic information systems is organized around data models: computational structures (rasters and vectors are common variants) that determine how GIS stores, organizes, and displays various types of information for different purposes. Put simply, data models treat the world in terms of objects that represent entities and their related attributes. In GIS, there is usually no dedicated model of the processes that govern dynamics, adaptation, and evolution of a system. For many years, GIS has advanced the potential for unifying representations of entities and processes, and recently, the long-standing promise of consociating the two is beginning to be realized, enabling a burgeoning paradigm shift to a new style of GIS.