Sharing and Accessing Biodiversity Data Globally
By Hannu Saarenmaa, Deputy Director for Informatics, GBIF Secretariat

The Global Biodiversity Information Facility (GBIF) opened its information system in early 2004. GBIF's data portal (www.gbif.org) now integrates tens of millions of records of primary biodiversity data from hundreds of databases worldwide in museums, botanical gardens, and observation networks such as those of bird watchers.
Primary Biodiversity Data and Its Uses—An Introduction
Making biodiversity data openly available on the Internet is GBIF's goal. It was started as the result of an Organisation for Economic Co-operation and Development megascience initiative but is now an independent international organization with a membership of 47 countries and 30 other international organizations.
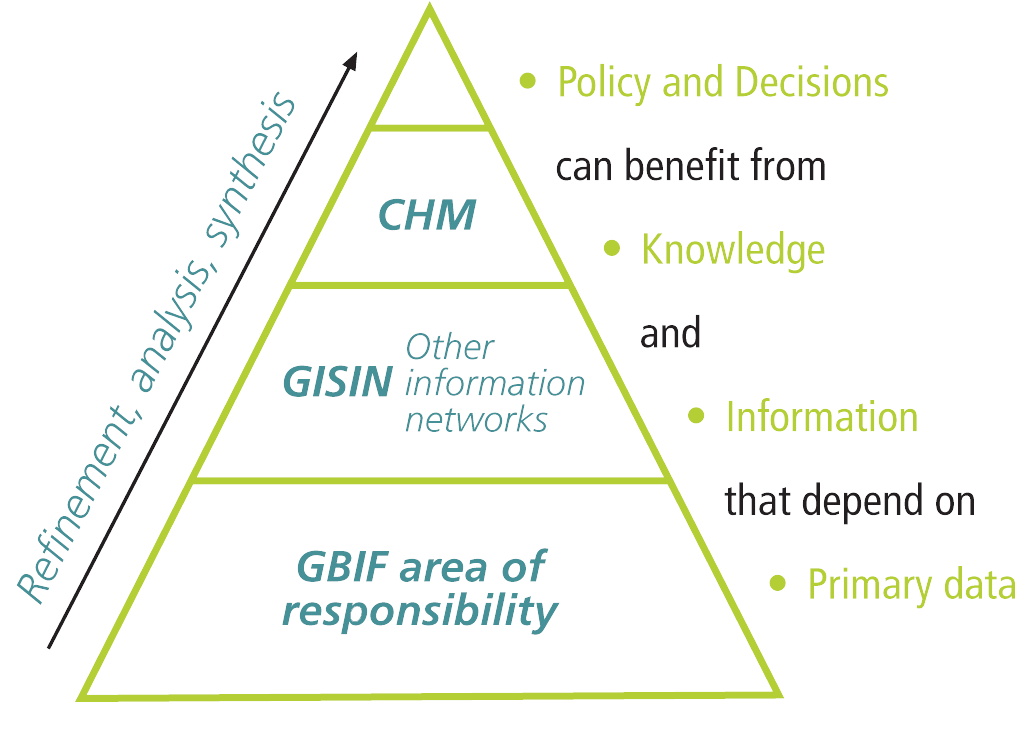
In its early phases, GBIF concentrated on primary biodiversity data—data that originates from field observations by bird watchers; vouchered specimens, such as those of botanical and zoological museums; systematic surveys, such as natural resource inventories; and other similar sources. The relationships of primary data with other types of data can be illustrated by the pyramid of information shown in the accompanying illustration. Because the databases of the data providers share features, such as scientific names for organisms and geographic attributes, the data can be integrated in different ways.
Primary biodiversity data represents a huge reuse value. It can be aggregated into distribution maps, provide retrospective views of species distributions, and be projected into the future based on various environmental change scenarios. Advanced techniques for doing these kinds of analyses are available, for instance, using the GARP tool for ecological niche modeling [i.e., the Genetic Algorithm for Rule-set Production tool that was originally developed by David Stockwell at the San Diego Supercomputer Center]. Such analyses have been used for projecting species invasions, designing reintroduction programs, understanding the effects of global climate and other types of change, understanding rare and endangered species' distributions, and designing biodiversity conservation plans. If data sharing through GBIF keeps growing at its current rate, it will be very useful for answering the big burning question about loss of biodiversity and help inform international agreements for reversing such trends by the year 2010.
Current Status of GBIF Data
The GBIF information system went online in early 2004 and after one and one-half years of operation, 73 million records of primary biodiversity data from 521 collections/databases  have been made available on 127 data providers by 35 GBIF participants. This data has been collected from 239 countries or territories. GBIF estimates that these figures represent only about 20 percent of existing digitized biodiversity data. While the data served via GBIF is still quite patchy, the gaps are being filled rapidly. The biggest gains have been achieved by linking with GBIF online observer systems, such as Cornell Laboratory of Ornithology, the United Kingdom's National Biodiversity Network, and the Swedish Species Gateway, and by connecting to existing thematic networks such as Ocean Biogeographic Information System (OBIS) and Mammal Networked Information System (MaNIS). have been made available on 127 data providers by 35 GBIF participants. This data has been collected from 239 countries or territories. GBIF estimates that these figures represent only about 20 percent of existing digitized biodiversity data. While the data served via GBIF is still quite patchy, the gaps are being filled rapidly. The biggest gains have been achieved by linking with GBIF online observer systems, such as Cornell Laboratory of Ornithology, the United Kingdom's National Biodiversity Network, and the Swedish Species Gateway, and by connecting to existing thematic networks such as Ocean Biogeographic Information System (OBIS) and Mammal Networked Information System (MaNIS).
The data providers share data using standard protocols and standard data exchange formats. For the latter, two XML schemas are currently used—Access to Biological Collections Data (ABCD) and Darwin Core. ABCD offers a complete metamodel for a biological collection with several hundreds of nested elements. Darwin Core is a minimal, flat schema with 48 elements. Naturally, both schemas include latitude and longitude, and among the current GBIF data, 74 percent actually does have values for these. Coordinate precision values are also available for about 10 percent of the current data.
Architecture and Components of the GBIF Information System
The GBIF information system is based on a Web services approach that uses distributed data providers, located via a central registry, and accessed by a central portal—all communicating using standardized XML messages. This standardization is done through the Taxonomic Databases Working Group (TDWG).
 |
| GBIF currently focuses on primary biodiversity data at the bottom of the information pyramid. |
Data providers must install wrapper software that maps the local database schema into ABCD or Darwin Core formats, translates XML-encoded queries coming from the Internet into SQL, and returns data or metadata the same way. The two currently supported protocols for this communication are BioCASE and DiGIR. Work is underway to build a successor for these protocols called TAPIR [i.e., TDWG Access Protocol for Information Retrieval] that will merge the best parts of each protocol. Simple Object Access Protocol (SOAP) is not being used (yet) because it would introduce extra overhead for moving around large datasets.
The data providers can announce their presence in the GBIF UDDI [Universal Description, Discovery, and Integration] registry at registry.gbif.net. This central service is based on a commercial tool from Systinet, Inc.  Anyone can install the data provider software and register. However, after registration, a node manager from an existing GBIF participant (i.e., coordinator from a country or organization) must endorse the data provider as somebody who is indeed sharing scientific biodiversity data. This is a rudimentary quality assurance step although the node manager does not currently scrutinize the actual data records. Before receiving this endorsement, GBIF does not make the data available, although the UDDI registry has open SOAP interfaces for other portals to discover the data providers. Anyone can install the data provider software and register. However, after registration, a node manager from an existing GBIF participant (i.e., coordinator from a country or organization) must endorse the data provider as somebody who is indeed sharing scientific biodiversity data. This is a rudimentary quality assurance step although the node manager does not currently scrutinize the actual data records. Before receiving this endorsement, GBIF does not make the data available, although the UDDI registry has open SOAP interfaces for other portals to discover the data providers.
GBIF operates a prototype data portal at www.gbif.net that can be used to search, browse, and drill into the data of endorsed data providers. This central gateway to GBIF data is multilingual and maintains a central index of the most important data elements common to data provider records. There also is a synonym resolution of organism names provided by the Catalogue of Life Partnership, although currently only about 30 percent of the species can be covered this way. The data portal currently does not offer XML data services, but as high-performance TAPIR implementations become available, these functionalities will be added.
Geographic Information Processing at GBIF
GBIF occurrence data can visualized uisng the Google Earth client. The data portal also offers links to some geographic visualization services provided by GBIF participants. All results of queries are sent to the Belgian Biodiversity Information Facility, which generates a simple GIF overview map showing the distribution of the data points. This service is based on MapServer and PostGIS.
There also are two levels of dynamic map service from the Canadian Biodiversity Information Facility (CBIF). Upon request by the user, data is sent from the GBIF data portal to a map server in Canada. In the original implementation, this service offered zooming, panning, and drilling into the entire records by clicking the dots shown on a world map layer from Demis, a company based in the Netherlands.
Recently, more functionality has been achieved through an experimental custom interface to GBIF's global index. This server offers Web Map Service (WMS) access to these records. The WMS service makes dynamic queries against the GBIF data portal based on scientific names entered by the user. The requirement for scientific names might inhibit some users, but one can search the GBIF names data to find the scientific name that corresponds to a common name. Multiple species layers can be plotted together on one map, using differing shapes, colors, and sizes of points selected by the user. Each of the plotted coordinates can be queried and returns the user to the GBIF data portal to retrieve information for a specific point using the GetFeatureInfo query.
Continued on page 2
|