Geographic data comes in all shapes and sizes. Finding the data you need for your project is one thing, but keeping track of it inside a project with dozens of maps and hundreds of layers can be difficult.
You can filter what you don’t need to see from the Contents pane, but maps are a visual experience. Sometimes you just don’t want to see a layer and you don’t want to keep having to make manual adjustments. What’s not currently drawing in the view still takes up space in the Contents pane and uses system resources.
To solve this dilemma, ArcGIS Pro 3.1 introduces catalog layers—a new layer type. Catalog layers may be useful for those who work with ArcGIS Pro maps or scenes that contain a large amount of data. This article shares an example of how catalog layers can be used.
It’s called a catalog layer because its purpose is to help you organize, or catalog, your datasets. A catalog dataset is created and stored in a geodatabase and establishes item references with the data it includes. The item references point to various data sources—from local or network file shares, or your Enterprise portal.
With catalog layers, data management tasks are minimal. You’re not breaking existing data connections or duplicating anything. Think of it this way: the catalog dataset is a file cabinet. Each item reference to a dataset, feature class, or service is a file in the cabinet. You’ll frequently pull out the files you want to see, and the ones you don’t need right now are put in the back of the cabinet—but they are still in the cabinet. This analogy can simplify your understanding of what is going on behind the scenes.
There are core aspects to creating catalog layers, such as item type filters, that aren’t covered in this article. To learn how you can create a catalog dataset and establish item references, you can read the web help documentation.
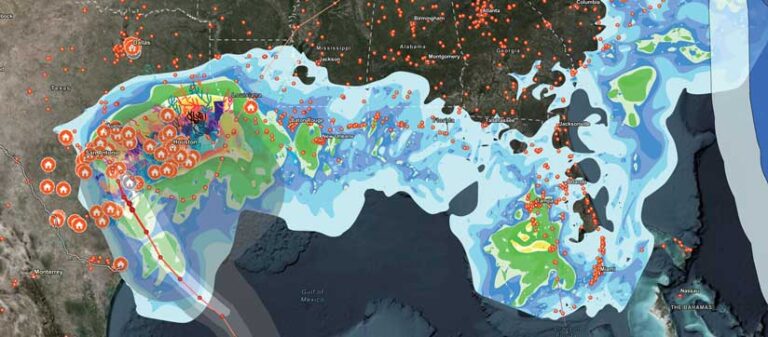
A Scenario Using Catalog Layers
Imagine you work for a natural disaster agency that collects data for an incoming Category 3 storm. You get data from models that constantly update their forecasts. The information evolves frequently and rapidly, and it comes in various stages. After the hurricane makes landfall, on-the-ground crews provide access to data they’ve collected to your agency. That data is collected at different times and in different formats. All this data adds up quickly. Every piece of data is important, but consuming all this data is a different story. Everyone involved in collecting, editing, and uploading the data has done their work, but now you must make something from it.
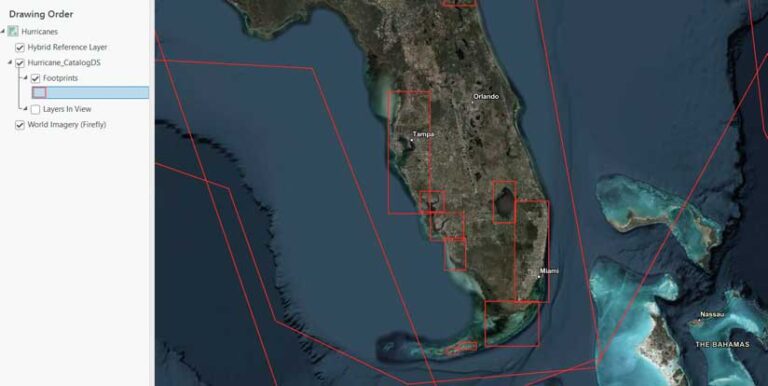
The file cabinet is overflowing—but you can manage it. In any map with a catalog layer, one of the two sublayers you will see is a Footprints layer. When the catalog dataset is created, it builds convex hull polygons of each item’s footprint and puts them into one feature layer. The footprints show the spatial extent of every item (like the footprints in a mosaic dataset). Any given layer’s spatial extent isn’t immediately clear when looking at a geodatabase or a service layer in a file directory.
If you right-click the catalog layer in the Contents pane and open its attribute table, you will see that each item is a record in the table. The Item Source field stores the path of the item. Meanwhile, the Item Type field tells you what kind of data it is. It’s like the files in your file cabinet tell you what’s inside without needing to open them. The other fields you see are detailed in the help documentation. You can also add fields.
The second layer in the catalog layer’s structure is named Layers In View. It is a composite sublayer that does exactly what the name implies. Catalog layers dynamically load layers in your map based on spatial, temporal, or range filters. If an item in your catalog layer is in view, it is listed in the Contents pane under the Layers In View heading.
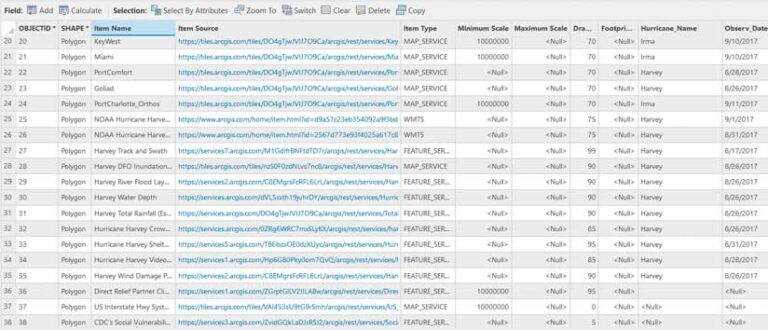
Items in the catalog layer appear in the Contents pane as you pan around the map. But which layers get drawn? That’s where the Feature Order Weight field in the catalog layer attribute table comes into play. Feature drawing order was introduced with the release of ArcGIS Pro 3.1. Catalog layers are included as one of the default fields. You can edit which items are drawn on top by giving them a larger value—like keeping your most important files toward the front of the file cabinet.
There are other ways to limit what gets drawn as well. You can modify the layer limit, or you can also set scale ranges for each item in your dataset. These settings will be reflected in your map as you change scales.
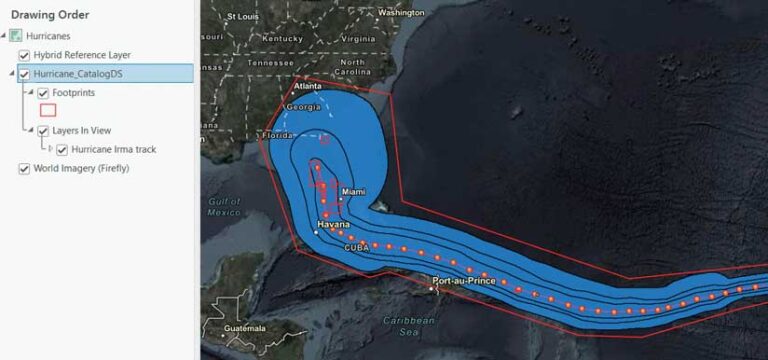
Lastly, the contents of a catalog dataset include feature classes, BIM files, and LAS datasets. Because each of these items are references to the data—not the actual items—there are limitations with what you can do with them. In almost all cases, consider catalog layer contents as read-only. That means you cannot view a sublayer’s attribute table, make edits to its features, or make changes to the symbology.
However, there is one solution. You can right-click any item reference in the catalog layer and choose Make Layer from Catalog Dataset Item. This builds the item as a separate layer in your map with all the functionality that normally comes along with it. Meanwhile, the item remains a member of the catalog dataset.
Takeaways
To summarize, consider adding catalog layers into your current workflows. Read the help documentation to learn more, and share your thoughts or use cases on the ArcGIS Pro page on Esri Community.