At ArcGIS Pro 3.0, we introduced the GeoAI toolbox, which brings new AI and machine learning algorithms to ArcGIS Pro. This toolbox contains eight geoprocessing tools that help to solve Natural Language Processing problems (Text Analysis Toolset – 6 tools), and classification and regression problems (Feature and Tabular Analysis Toolset – 2 tools).
In this blog article, we’ll focus on the six tools within the Text Analysis toolset, which are designed to work with unstructured text data using Natural Language Processing (NLP) techniques. We’ll first get a brief introduction to unstructured text data and its intersection with GIS, we’ll then define NLP and explore some common NLP tasks, then wrap up by walking through some workflows that use the new Text Analysis tools to solve real-world NLP problems.
Unstructured text data and GIS
As GIS professionals, we are very accustomed to working with three main data types: vector data, tabular data, and raster data. Generally, we refer to vector and tabular data as “structured”, meaning that it is highly organized into rows and columns, has a predefined data model, and is easily searchable. Raster data is commonly referred to as “unstructured”, in that it does not have a predefined data model or schema, and is difficult to search. The table below shows some common vector, tabular, and raster data formats used in ArcGIS Pro.

Another example of unstructured data is text. This is free-flowing language that lacks the row/column structure of vector and tabular data. Text is found almost everywhere–in books and journals, news articles, metadata, text messages, Word documents/PowerPoint slides, PDFs, medical records, customer surveys, invoices, and of course all over the internet on websites, social media posts, instant messages, and emails. What’s really interesting for us as GIS professionals is that many forms of unstructured text actually contain location information such as coordinates, addresses, place names, geographies, etc. Take for example the event below scraped from the City of Philadelphia website:

Is there meaningful locational or geographical information in this unstructured text example? Is there any additional information that we can extract from this text? Is it possible to pull this unstructured information and have it logically organized into a structured table with rows and columns?
Natural Language Processing (NLP)
The answer is yes, and one of the state-of-the-art ways to do it is using Natural Language Processing (NLP). NLP is a field of computer science concerned with the processing and analysis of natural language text. It’s about giving computers the capacity to understand and learn from written text and spoken word in a similar fashion to humans. From its beginnings in the 1950s, the study of NLP has evolved from linguistic theory and small scale technological prototypes to handwritten rule-based systems in the 1980s, and eventually to statistical and machine learning methods as computer technology improved into the 1990s and 2000s. Since the early 2010s, NLP has been primarily accomplished using deep learning. Deep neural networks solve complex problems by breaking them down into multiple, simple levels of representation (e.g. layers) and sequentially learning more about the problem at each level. This type of architecture is particularly well suited for working with text data, which is itself a sequence of words or phrases that transpire over time. Some common NLP tasks include:
- Named-entity Recognition – extracting information contained in text documents
- Machine Translation – translating input text in one language to another
- Text Classification – categorizing and organizing text documents
- Text Summarization – shortening or summarizing long pieces of text to keep only the main points
- Question Answering – providing an answer to a question
- Text Generation – generating a text sequence that completes or finishes a text sequence or paragraph
- Masked Language Modeling – providing a suggestion for a missing word in a sentence
In the following sections, we’ll have a look the new Text Analysis tools in terms of the overall task they complete and then see some specific use cases and applications.
Named-entity Recognition
Task:
- Extract recognizable and named entities from unstructured text documents such as organizations, names, dates, countries, addresses, coordinates, crime types, location, etc.
Tools:
- Train Entity Recognition Model – trains a named-entity recognition model to extract a predefined set of entities from raw text.
- Extract Entities Using Deep Learning – runs the trained entity recognizer model on text files to extract entities and locations into a structured table, and optionally geocodes the locations.
Use cases and applications:
- Street address extraction from 911 call reports, police reports, fire reports, public works reports, event lists, etc.
- Information extraction from text: emails, websites, instant messages, social media posts, news articles, academic papers, etc.
Example use case:
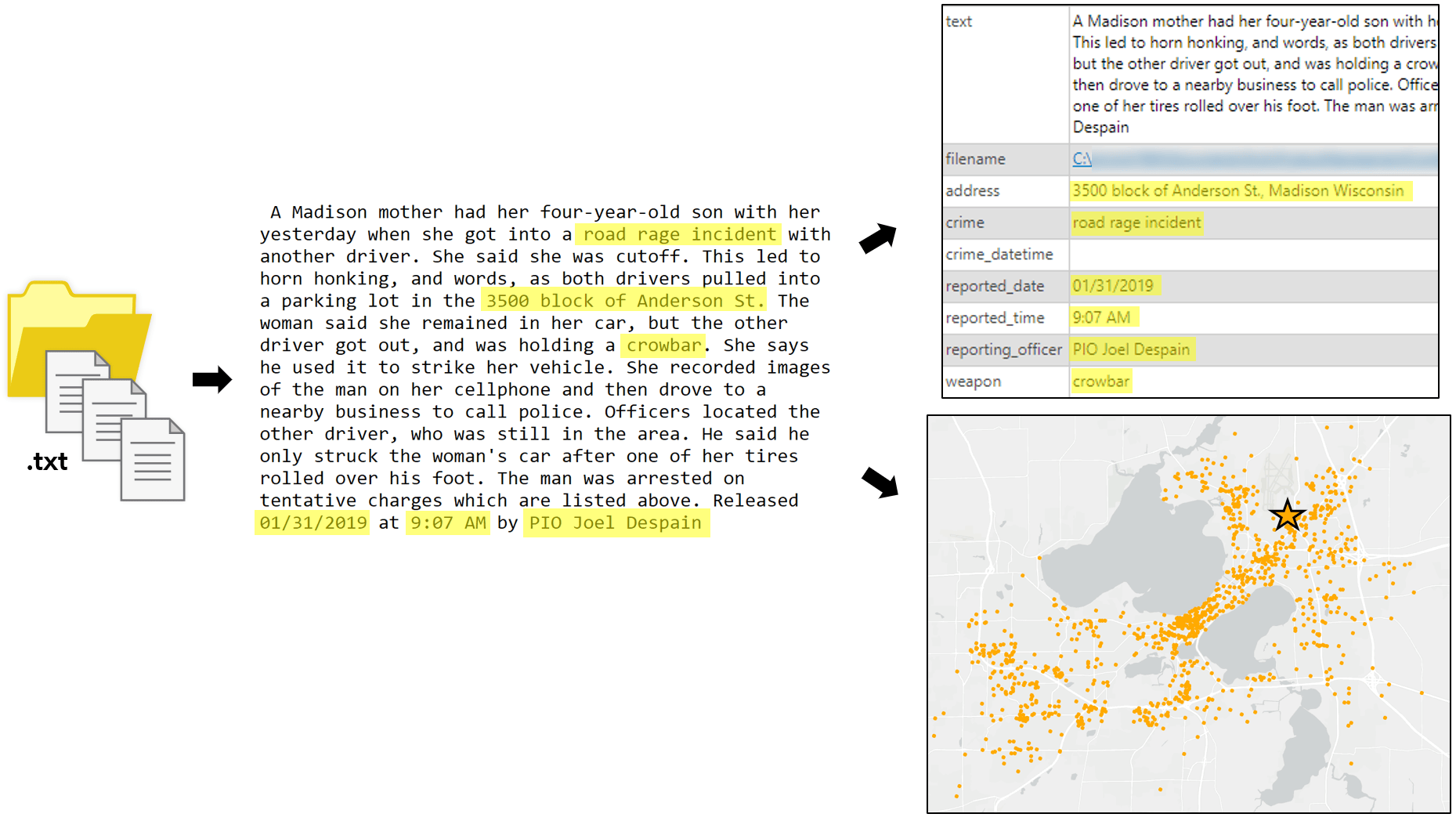
The example below shows a folder full of text files containing crime incident reports from the city of Madison, Wisconsin, USA. Each report may contain information related to the location of the crime, the crime type, the date and time of the crime, if there was a weapon used, and who the reporting officer was. The new named-entity recognition tools can be used to train a NLP model to extract several entities from each report into a structured table, and then geocode the locations of the crimes to produce a map.
Machine Translation
Task:
- Translate an input sentence to an output sentence of any length.
Tools:
- Train Text Transformation Model – trains a text transformation model to transform, translate, or summarize text.
- Transform Text Using Deep Learning – runs the trained sequence-to-sequence model on a text field in a feature class or table and updates it with a new field containing the converted, transformed, or translated text.
Use cases and applications:
- Translate a sentence in English to another language.
- Summarize long pieces of text to keep only the main points.
Text Classification
Task:
- Assign tags/labels to unstructured text (single-label or multi-label).
Tools:
- Train Text Classification Model – trains a text classification model to assign a predefined category or label to unstructured text.
- Classify Text Using Deep Learning – runs the trained text classification model on a text field in a feature class or table and updates each record with an assigned class or category.
Use cases and applications:
- Email into “spam” and “ham”.
- Newspaper articles into “sports”, “political”, “local”.
- Country names from incomplete addresses.
- Tagging inappropriate/toxic comments.
- Sentiment analysis on movie reviews, social media posts, etc.
- Language detection from text.
- Assign customer support tickets based on priority level.
Example use case:
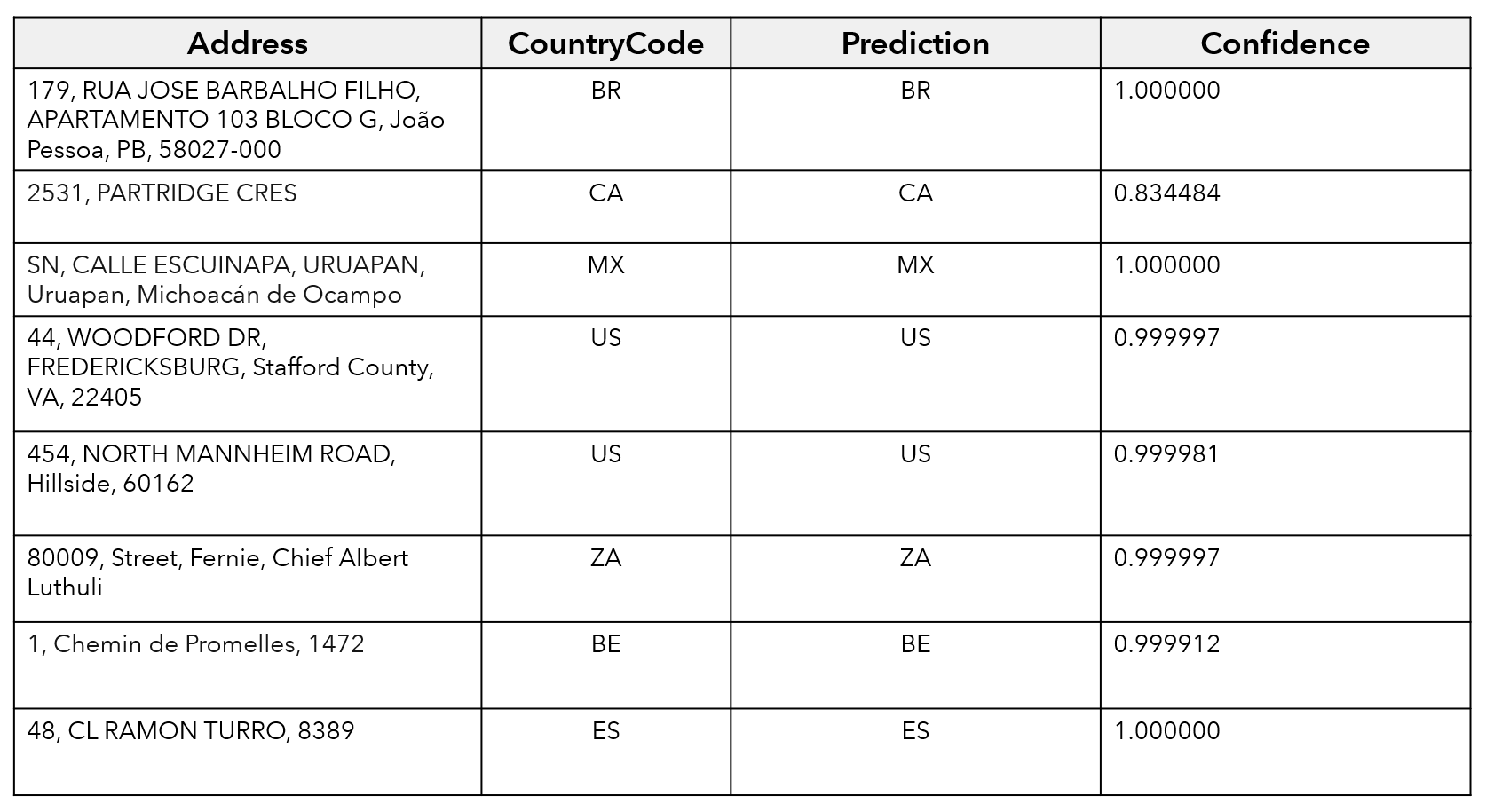
The example below highlights the use of text classification to predict the country associated with an address. The “Address” field contains information for street, number, and town, but is incomplete because it is missing the country. As a result, it will be difficult to geocode these locations. This task is further complicated by the fact that the addresses occur in several different languages. The new text classification tools can be used to train a NLP model to identify the country associated with each incomplete address based on a sample of correctly assigned addresses provided by the user, then append it as a new column to the table.
Conclusions and resources
So that is a brief background on unstructured text data, its use cases in GIS, and some common Natural Language Processing (NLP) tasks that are available in the Text Analysis toolset of the new GeoAI toolbox.
In addition to these tools, we have also released pretrained deep learning models for text analysis/NLP tasks. These pretrained models aim to eliminate some of the most challenging and time consuming manual aspects of deep learning, such as collecting training data, processing time, and compute resources, etc. Currently, the three pretrained NLP models available on the ArcGIS Living Atlas of the World perform address standardization, country classification, and named-entity recognition workflows, and can be used directly within the Transform Text Using Deep Learning, Classify Text Using Deep Learning, and Extract Entities Using Deep Learning tools, respectively.
In future blog articles, we’ll go through a more detailed, step-by-step walkthrough of some specific workflows for named-entity recognition, text translation, and text classification. Stay tuned!
We are excited to hear your feedback about the tools in the new GeoAI toolbox!


Article Discussion: