The purpose of the ArcGIS Pro 3.2 release is to improve your user experience and productivity when using deep learning tools included in the Image Analyst extension. We introduced new experiences for training sample creation, model training, and inferencing. Additionally, we have significantly enhanced the capabilities for training models. Here is an overview of the new deep learning features in this release:
- Dynamic image collection layer for labeling training data
- Enhanced user experience to train and review deep learning models
- Train Deep Learning Model wizard
- Review Deep Learning Model pane
- Improved user experience for the Train Deep Learning Model geoprocessing tool
- Productivity enhancements for training
- Data augmentation for both training and validation
- Weight initialization scheme to build better models for multispectral imagery.
- Automatic batch size adjustment per GPU memory availability
- Support for Cloud Storage connections
- Multiple GPU on single machine for select model types
- Improved model types
- Better support for inferencing for oblique images
- End-to-end workflow documentation
Dynamic image collection layer for labeling training data
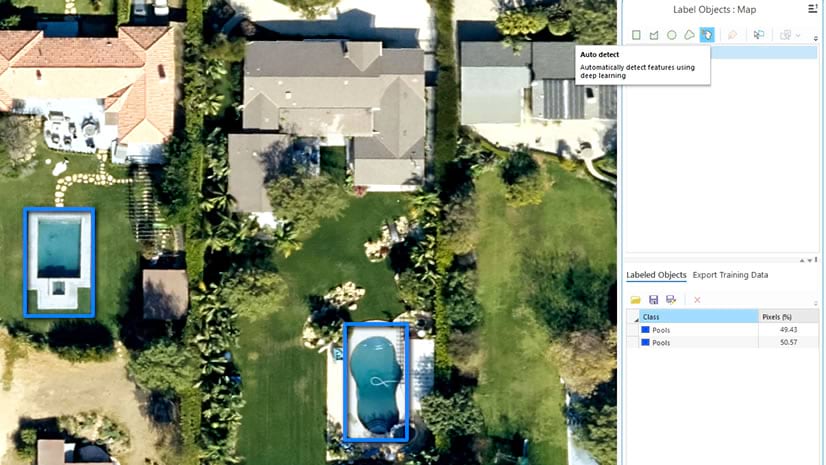
In some cases you may need to create labels on multiple images. This workflow is supported through the Image Collection option. However previously, you would create a mosaic dataset first, and then use it as an image collection.
Now, you no longer have to create a mosaic dataset. When you open the Label Objects for Deep Learning tool, it will ask you to either use an existing Imagery layer or create a new image collection layer. When creating a new image collection, you can now simply point to a folder containing images, and the tool will automatically create an image collection layer; allowing you to label faster and easier.

Enhanced user experience to train and review deep learning models
The new Train Deep Learning Model wizard and Review Deep Learning Models pane can be launched from the Imagery tab, under the Deep Learning tools. Additionally, the Label Objects for Deep Learning pane is also available in the Deep Learning tools.

Train Deep Learning Model wizard
The Train Deep Learning Model wizard is an assisted workflow to help you train deep learning models. The wizard consists of three pages: Get Started, Train, and Result.
On the Get Started page, you specify how to train the model. You have two options:
- Set the parameters automatically: This option allows the software to try different model types, parameters, and hyperparameters to build the best model within a given time frame.
- Specify my own parameters: With this option, you have full control over setting the model type, parameters, and hyperparameters, giving you more control over the training process.

On the Train page you set your input, output and optional parameters, and then run the tool. Here you can see the progress of the tool while it’s running. Once the training is complete, the Result page displays the details of the model. You also have the option to compare it with other models.

Review Deep Learning Model
Reviewing a model provides insights into its training process and potential performance. In certain cases, you may have multiple models at hand for comparison. The Review Deep Learning Model pane is an additional user interface to allow you to review existing models.

Improved user experience of the Train Deep Learning Model geoprocessing tool
We have made several improvements to the Train Deep Learning Model tool; enhancing both its appearance and functionality. The grouping of various parameters has been redesigned to provide a more intuitive user experience. The parameters are now organized into two groups: Data Preparation and Advanced. However, the most important parameters that are frequently modified are located at the top of the tool.

Productivity enhancements for training
Besides the look and feel of the tool, there are also major productivity enhancements:
- Data augmentation
- Weight initialization scheme
- Automatic bath size adjustment per GPU
- Support for Cloud Storage connections
- Support for Multiple GPUs
- Improved model types
Data Augmentation
Data augmentation is a technique to reduce overfitting when training a model. It involves artificially increasing the size of a dataset by randomly changing properties such as rotation, brightness, crop, and more of the image chips. The tool now offers the capability to perform user-defined data augmentation for both training and validation data. Also, you have greater control over how data augmentation is applied. you can choose from options such as default settings, no augmentation, customization of existing methods, or utilize a JSON file containing many data augmentation methods supported by vision transforms. In the below image, we are showing some image augmentation examples on a GCP Marker image chip.

Weight Initialization Scheme
Weight Initialization Scheme is a new parameter to build better models for multispectral imagery. You can specify the scheme in which the weights will be initialized for your data.
Automatic batch size adjustment per GPU memory availability
Now the tool can adjust batch size based on the available GPU memory of the machine.
Support for Cloud Storage connections
It also now supports input training data and output models from Cloud storage connections.
Multiple GPU on single machine for select model types
By default, the tool uses all available GPUs on the machine for the following commonly used model types: ConnectNet, Feature classifier, MaskRCNN, Multi Task Road, Extractor, Single Shot Detector, U-Net. To use a specific GPU, you can use the GPU ID environment.
Improved model types
Now you can use Super Resolution for multispectral datasets. We have improved support for MMSegmentation and MMDetection.
Better support for inferencing on oblique images
Oblique or street view images have more contextual details of objects on the ground compared to ortho images. Therefore it’s better to perform inferencing in Pixel Space and transform it to Map Space. This workflow is supported for image collections (mosaic datasets) that contain images with frame and camera information. Such image collections are created using the ortho mappinag functionality in ArcGIS Pro, or ArcGIS Drone2Map. However, these image collections contain a lot of overlapping images, and we may not need inferencing on duplicate images. At Pro 3.2, we have added a new Processing Mode called Process candidate items only. You can use this new processing mode to detect objects (or, classify pixels) only on select images in the image collection.
The Compute Mosaic Candidates tool can be used to find the image candidates that best represent the mosaic area. The tool adds a new column called Candidates, when you use the Process candidate items only processing mode, only the images identified in the Candidates columns are used.
Documentation
We have also improved our user documentation for deep learning for the Image Analyst extension:
- Step by step key end-to-end workflows for Object Detection, Classify Pixels, Classify Objects, and Change Detection
- More details on Arguments for training and inferencing
- More details on various supported deep learning model types
What do you think about these enhancements? Do you have any use cases that can benefit from these new features? Please share your ideas to improve deep learning workflows in ArcGIS.






Article Discussion: